Artificia intelegence, final project
Статистика употребления алкоголя по регионам
Я выбрал эту тему, так как проблема потребления и злоупотребления алкоголя всегда являлась актуальной.
Для своего проекта я использовал открытую базу данных «World Health Organiztion»
Этапы работы
В проекте используется датасет содержащий данные о потребление алкоголя на душу населения (15+) (в литрах чистого алкоголя)
- Есть ли статистически значимая прямая связь между регионом проживания и граммами употребления алкоголя? - Есть ли статистически важные различия в регионах по потребления грамм алкоголя? - Статистически устойчив ли рост потребления по регионам?
Сначала я загрузил данные через библиотеки Pandas. Проверил работоспособность структур данных и удалил пропущенные значения и тп. В общем привел код и данные в порядок. И потом агрегировал данные по регионам и годам.
С этим мне отчасти помогал искусственный интеллект СhatGPT. (Пример промпта: «Нужно исправить ошибку в коде (далее ошибка)»)
Части кода:
import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv («alcohol_consumption.csv») df.head ()
df.info () df.describe () df.describe ()
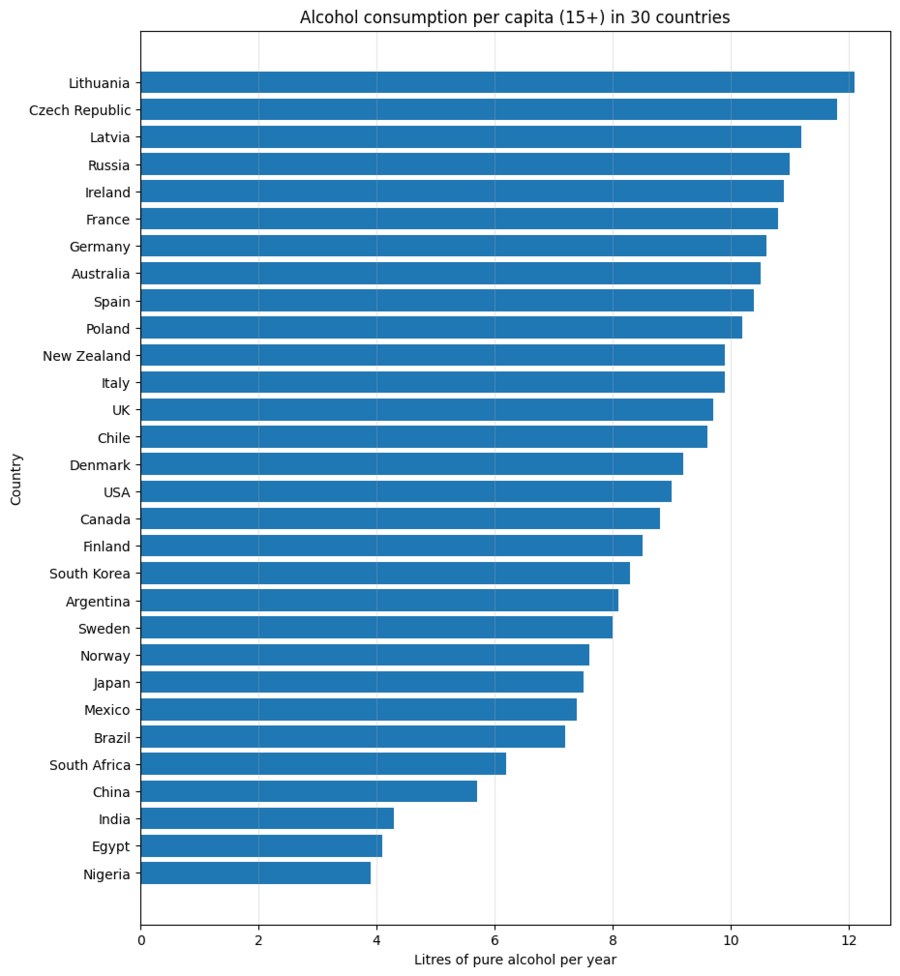
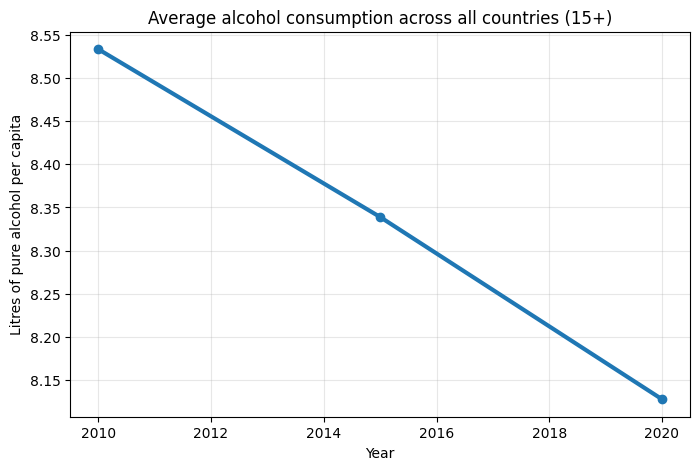
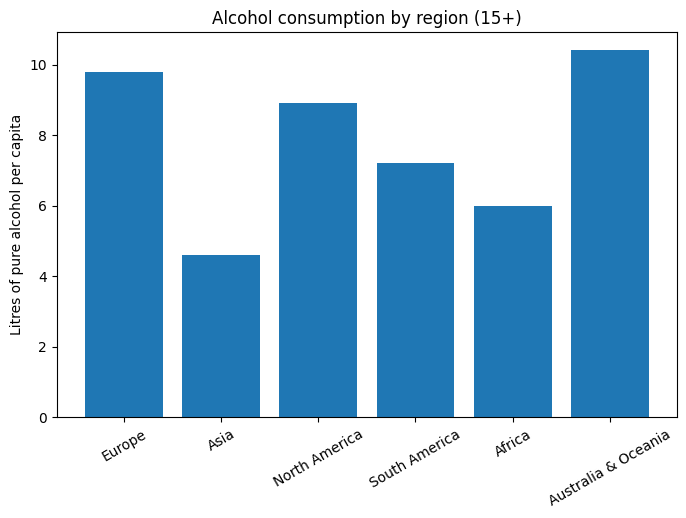

Графики: «Потребление алкоголя в мире», «Потребление алкоголя по регионам», «Потребление алкоголя по регионам во времени», «Потребление алкоголя по странам».
Статистические гипотезы подтверждаются, но не полностью, заметен спад употребления алкоголя и отличия по регионам, но закономерность в употреблении не выявлена
В ходе работы использовалась генеративная модель ChatGPT (OpenAI) для: - помощи в структурировании анализа - формулировки исследовательских вопросов - пояснения методов обработки данных
Модель использовалась как вспомогательный инструмент.



