
Аналитика глобального потребления кофе
Вводная часть

Какие данные были выбраны и где они были найдены
Для данного проекта был выбран табличный датасет Coffee Domestic Consumption, содержащий информацию о внутреннем потреблении кофе в разных странах мира за несколько лет. Датасет представлен в формате CSV и включает данные по странам, годам и объёмам потребления кофе.
(Датасет найден на сайте kaggle https://www.kaggle.com/datasets/waqi786/worldwide-coffee-habits-dataset)
Почему именно эти данные были интересны для анализа
Потребление кофе — это показатель, который связан не только с питанием, но и с образом жизни, культурой, экономическим развитием и повседневными привычками людей.
Анализируя потребление кофе по странам и во времени, можно увидеть различия между регионами мира, выявить страны-лидеры и понять, как глобальные тенденции меняются со временем.
Эти данные показались мне интересными, потому что я делаю дипломную работу — институцию-исследование любительского кофе. Эти данные и графики могут помочь по-другому взглянуть на мою тему и расширить мои знания в этой области для успешной реализации дипломного проекта.
Какие виды графиков были выбраны и почему
Для визуализации данных были выбраны следующие типы графиков:
1. Столбчатая диаграмма — для сравнения стран по объёму потребления кофе (наглядно показывает лидеров).
2. Линейный график — для отображения динамики потребления кофе по годам.
3. Облако тегов (word cloud) — для визуального выделения стран, которые потребляют больше всего кофе.
4. Столбчатая диаграмма по годам — для анализа глобального потребления кофе во времени.
Такие типы графиков были выбраны, потому что они просты для восприятия и хорошо подходят для сравнительного анализа по годам употребления кофе и для наглядной разницы в употреблении кофе странами.
Этапы работы
Как я обрабатывал данные (поэтапно) и как строил графики
1) Загрузка датасета и базовая проверка
Сначала я загрузил CSV-файл в Google Colab и посмотрел, какие колонки есть в таблице, чтобы понять структуру данных и какие столбцы отвечают за страны и годы.
2) Выделение колонок с годами и приведение данных к числовому формату
В датасете потребление кофе хранится по годам в отдельных колонках, например 2018/19, 2019/20 и т. д. Я выбрал только те колонки, которые начинаются с 4 цифр (то есть выглядят как год), и затем перевёл значения в числа (на случай, если в CSV они были строками).

3) Подсчёт суммарного потребления кофе по каждой стране
Чтобы сравнивать страны между собой, я создал новый столбец Total, который показывает суммарное потребление кофе за все годы, которые есть в датасете. Это даёт единый показатель для ранжирования стран.

4) График 1: Топ-10 стран по потреблению кофе
Далее я сгруппировал данные по стране, посчитал суммарное потребление и выбрал 10 стран с самым высоким значением. После этого построил столбчатую диаграмму, так как она лучше всего подходит для сравнения стран.
5) Подготовка данных для анализа по годам
Чтобы посмотреть глобальную динамику, я сложил потребление по всем странам для каждого года. Это помогает увидеть общую тенденцию: растёт ли мировое потребление кофе или нет.

6) График 2: Глобальное потребление кофе по годам (столбчатая диаграмма)
Для наглядности я использовал столбчатую диаграмму — она показывает вклад каждого года и удобно читается, когда на оси X категориальные значения (названия годов в формате 2018/19).
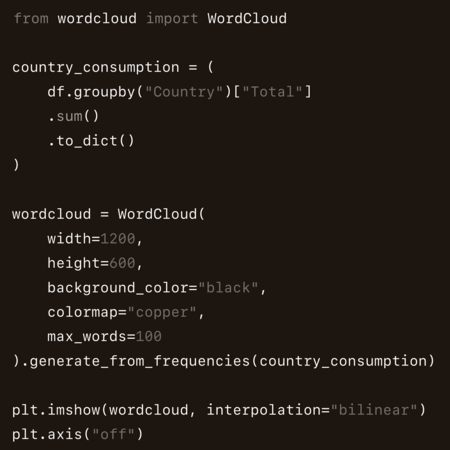
7) График 3: Облако тегов стран — основных потребителей кофе
Для облака тегов я использовал данные из страны и суммарного потребления. Смысл облака в том, что чем больше потребление, тем крупнее слово (страна). Это визуально показывает концентрацию потребления и выделяет лидеров.

8) График 4: Динамика глобального потребления кофе (линейный график)
Чтобы показать взаимосвязь «год → потребление», я построил линейный график по данным global_by_year. Линейный график лучше всего подходит для временной динамики, потому что он показывает тренд и изменение значения по годам.
9) Единый стиль графиков
Чтобы визуализация выглядела цельно, я настроил общий стиль: тёмный фон и коричневая палитра (ассоциация с кофе). Это помогает сделать инфографику более консистентной и аккуратной.
Использование нейросетей
В процессе работы использовалась нейросеть ChatGPT (https://chatgpt.com) для:
1. Помощи в исправлении ошибок и отладке кода на Python (ошибок было очень много и голова немного кипела)
2. Помощь в структуризации и создании «красивого» кода с хэшами
3. Помощь в исправлении ошибок при использовании обозначения годов при создании графиков типа 2019/20
Стилизация графиков
Для всех графиков был выбран единый визуальный стиль с использованием коричневых оттенков, ассоциирующихся с кофе. Стилизация выполнялась средствами библиотек Matplotlib и Seaborn: были изменены цвета фона, графиков, подписей осей и текста. Целью было создание визуально цельной и аккуратной инфографики, отличающейся от стандартных графиков Python.
Изучающий и объясняющий формат визуализации
Каждый график был построен таким образом, чтобы:
1. его можно было понять без дополнительных пояснений,
2. он отвечал на конкретный вопрос (какие страны лидируют, как меняется потребление со временем и т. д.),
3. визуально подчёркивал ключевые различия и тенденции.
4. Графики сопровождаются подписями осей и заголовками, что делает их удобными для анализа и презентации.
Используемые статистические методы
В проекте применялись базовые статистические методы:
1. суммирование данных 2. группировка по странам и годам 3. сравнение значений между категориями
Сложные статистические модели не использовались, так как цель проекта — наглядная визуализация данных.
Итоговые графики
В рамках проекта были построены следующие визуализации:
1. Топ-10 стран по суммарному потреблению кофе 2. Глобальное потребление кофе по годам 3. Облако тегов стран — основных потребителей кофе 4. Линейный график динамики мирового потребления кофе
Все графики выполнены в едином стиле и отражают разные аспекты анализа выбранных данных.
Топ-10 стран по суммарному потреблению кофе
Глобальное потребление кофе по годам
Облако тегов стран — основных потребителей кофе
Линейный график динамики мирового потребления кофе
Источники информации
Датасет Worldwide Coffee Habits Dataset https://www.kaggle.com/datasets/waqi786/worldwide-coffee-habits-dataset



