
Анализ данных NBA
Введение
Для выполнения данной исследовательской работы была выбрана тема анализа статистических данных Национальной баскетбольной ассоциации (NBA). Статистика NBA является одной из наиболее подробных и доступных среди профессиональных спортивных лиг, что делает её удобной для изучения, обработки и визуализации. Большое количество показателей, таких как очки за игру, процент побед, эффективность бросков и влияние домашней площадки, позволяет исследовать взаимосвязи между результативностью команд и их успешностью. Использование этих данных даёт возможность проследить изменения в игре команд с течением времени и выявить общие тенденции развития лиги. Такой подход обеспечивает наглядное представление результатов анализа и способствует более глубокому пониманию закономерностей в профессиональном баскетболе.

Для проведения анализа была использована таблица со статистическими данными матчей команд NBA, сохранённая в формате CSV. На начальном этапе данные были загружены в рабочую среду с использованием библиотеки pandas, после чего сформирован единый датафрейм, содержащий информацию по каждому матчу и каждой команде. В таблице представлены такие показатели, как название команды, город, тип матча (домашний или гостевой), количество сыгранных минут, реализованные и выполненные броски, процент попаданий, набранные очки, показатель «плюс-минус», эффективный процент бросков (eFG%), а также дополнительные игровые метрики. После загрузки данных была выполнена первичная проверка структуры таблицы, включая просмотр первых строк и анализ количества столбцов. Это позволило убедиться в корректности импорта данных и наличии всех необходимых признаков для дальнейшего исследования. Полученный набор данных послужил основой для последующей агрегации показателей по сезонам и командам, а также для построения всех визуализаций, представленных в работе.

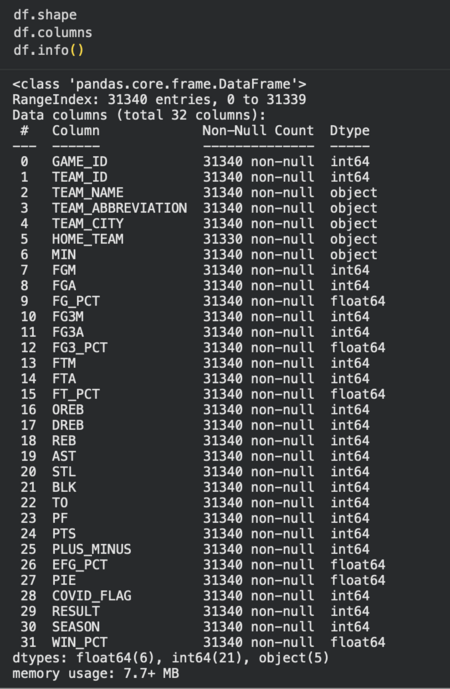
После загрузки данных был выполнен этап анализа структуры таблицы. На этом этапе определялись размер датасета, количество признаков и их типы, что позволило получить общее представление о содержимом и масштабах выборки. В результате было установлено, что набор данных содержит более 30 тысяч наблюдений и 32 столбца, включающие как числовые игровые показатели, так и текстовые характеристики команд. Дополнительно была проверена корректность типов данных и отсутствие значительных пропусков, что подтвердило готовность датасета к дальнейшему анализу и построению визуализаций.
На этапе предобработки данных были выполнены основные действия по приведению набора к удобному и унифицированному виду. Названия столбцов были переведены на русский язык и приведены к единому формату без пробелов, что упростило дальнейшую работу с данными и повысило их читаемость. Дополнительно были преобразованы ключевые признаки: сезон приведён к читаемому годовому формату, определён признак домашнего матча, а числовые показатели переведены в корректные числовые типы. Также при необходимости был выполнен перевод дат в формат datetime. Проведённая предобработка обеспечила корректность данных и подготовила датасет к последующему анализу и визуализации.
Настройка шрифта. На данном этапе был подключён внешний шрифт Manrope, который используется для всех последующих визуализаций. Это позволило обеспечить единый и аккуратный стиль подписей, заголовков и текстовых элементов графиков.
Настройка цветовой схемы и параметров отображения. Далее была задана общая цветовая палитра графиков, включая фон, цвета осей и пользовательскую цветовую карту. Также были установлены глобальные параметры отображения matplotlib, такие как цвет подписей, отключение лишних рамок и разрешение изображений, что улучшило визуальное восприятие графиков.
Стилизация осей графиков. На заключительном этапе была реализована функция оформления осей, добавляющая сетку и унифицирующая внешний вид линий и границ. Это позволило сделать графики более читаемыми и визуально согласованными между собой.
Получившиеся графики
Средняя результативность команд NBA по сезонам (2012–2024)
Для построения данного линейного графика использовались данные о среднем количестве очков, набираемых командами NBA за игру в каждом сезоне с 2012 по 2024 год. На первом этапе данные были сгруппированы по сезону, после чего для каждого сезона было рассчитано среднее значение очков за игру по всем командам. Это позволило получить обобщённую характеристику атакующей результативности лиги в разные годы. После вычисления средних значений сезоны были упорядочены по хронологии, что дало возможность отследить динамику изменения результативности во времени. Для визуализации была выбрана линейная диаграмма, так как она наиболее наглядно показывает тренды и изменения показателя от сезона к сезону. Дополнительно использовалась цветовая градация линии, чтобы визуально подчеркнуть развитие показателя на протяжении рассматриваемого периода. Для обработки данных применялась библиотека pandas, а для построения графика — matplotlib.
Распределение очков команд NBA: домашние и гостевые матчи (violin plot)
Для данного графика использовались данные о количестве очков, набираемых командами NBA в домашних и гостевых матчах. На этапе подготовки данные были разделены на две выборки в зависимости от типа матча: домашний или гостевой. Это позволило сравнить распределения очков в разных игровых условиях. Для визуализации был выбран violin-график, так как он одновременно отображает форму распределения данных, плотность значений и основные статистические характеристики. Такой тип графика даёт более полное представление о распределении, чем обычные столбчатые диаграммы. Цветовое разделение использовалось для упрощения сравнения между домашними и гостевыми матчами. Обработка данных выполнялась с помощью pandas, визуализация — средствами seaborn и matplotlib.
Топ-10 команд по эффективности бросков (eFG%) — сезон 2024
Для данного горизонтального столбчатого графика использовались данные об эффективном проценте попаданий (eFG%) команд NBA за сезон 2024. На первом этапе данные были отфильтрованы по выбранному сезону, после чего команды были отсортированы по значению eFG% в порядке убывания. Это позволило выделить десять наиболее эффективных команд по данному показателю. После сортировки были отобраны только первые десять команд, что упростило восприятие информации и позволило сосредоточиться на лидерах. Для визуализации была выбрана горизонтальная столбчатая диаграмма, так как она удобна для отображения рейтингов и позволяет легко читать названия команд. Дополнительно значения eFG% были подписаны рядом со столбцами для повышения информативности графика. Для обработки данных использовалась pandas, визуализация выполнялась с помощью matplotlib.
Связь результативности и успеха: очки vs процент побед (scatter plot)
Для построения данного графика использовались данные о среднем количестве очков за игру и проценте побед команд NBA за сезон. Каждая точка на графике представляет собой пару значений «команда–сезон». На этапе подготовки данные были объединены таким образом, чтобы каждому наблюдению соответствовали оба показателя. Для анализа взаимосвязи была выбрана точечная диаграмма, так как она позволяет наглядно оценить характер зависимости между двумя количественными переменными. Дополнительно на график была нанесена линия линейной регрессии, а также рассчитан коэффициент корреляции Пирсона, который отражает силу и направление связи между результативностью и процентом побед. Такой подход позволяет не только визуально, но и количественно оценить взаимосвязь показателей. Для обработки данных применялась pandas, для визуализации — matplotlib и seaborn.
Распределение очков команд за игру: сравнение сезонов (boxplot)
Для данного графика использовались данные о количестве очков, набираемых командами NBA за игру в разных сезонах (2012, 2016, 2020 и 2024). На этапе подготовки данные были сгруппированы по сезону, что позволило сравнить распределения результативности в разные временные периоды. Для визуализации была выбрана коробчатая диаграмма, так как она эффективно отображает изменения медианы, разброса и выбросов между сезонами. Такой подход позволяет выявить общий рост результативности лиги, а также изменения в вариативности очков с течением времени. Использование разных цветов для каждого сезона упрощает сравнение и делает график более наглядным. Для обработки данных использовалась библиотека pandas, визуализация — matplotlib и seaborn.



