Анализ и визуализация Global Disaster Events 2022–2025
Блокнот Google Colab
В датасете 13 признаков: тип бедствия, страна и координаты, дата, уровень (1–10), пострадавшее население, экономический ущерб (USD), время реагирования, факт оказания помощи, индекс разрушения инфраструктуры (0–1), и бинарная метка major disaster.
Тема интересна тем, что в одном наборе можно связать «что произошло» (тип/география/время) с «последствиями» (ущерб/пострадавшие/разрушения) и «реакцией» (скорость ответа и помощь). Это удобно для обучающей визуализации: можно показать, как из сырых событий получаются выводы, и какие метрики лучше использовать (например, медиана вместо среднего при перекошенных распределениях).
График 1 — Динамика событий по годам
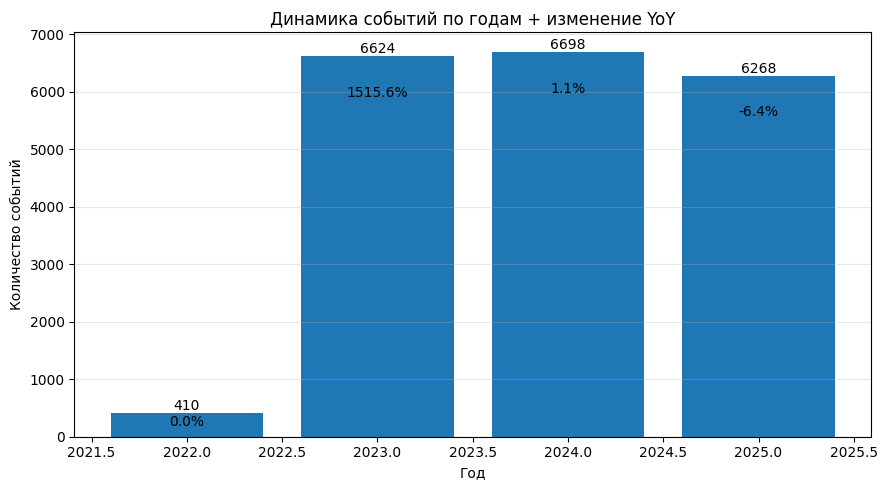
Цель: понять, как меняется количество событий в датасете по годам и есть ли заметные скачки.
Что сделано в коде:
Привели date к типу datetime и извлекли year.
Посчитали частоты событий по годам через groupby («year»).size () — это базовая агрегация (descriptive analysis).
Посчитали динамику:
yoy_abs = diff () — абсолютное изменение количества событий год к году.
yoy_pct = pct_change () — процентное изменение (YoY, year-over-year).
Как читать график
Высота столбца = сколько событий в датасете приходится на соответствующий год.
Число над столбцом = точное количество событий.
Процент внутри столбца = YoY: насколько год изменился относительно предыдущего.
Что видно по результату
В 2023–2025 объём событий держится на сопоставимом уровне (около 6–7 тысяч событий в год).
В 2025 видно снижение относительно 2024.
Почему 2022 год «аномальный» и даёт гигантский YoY
2022 в датасете — неполный год. По диапазону дат файл начинается в конце 2022 года (примерно с 08.12.2022) и заканчивается в конце 2025 года (примерно 07.12.2025).
В 2022 попадает только небольшой «хвост» декабря, то есть наблюдений физически мало.
Из-за этого переход 2022 → 2023 сравнивает частичный год с полным годом, поэтому YoY получается искусственно завышенным.
График 2 — Частота по типам
Горизонтальная столбчатая диаграмма сравнивает сколько событий каждого типа встречается в датасете за период 2023–2025. Каждый тип окрашен в отдельный цвет, чтобы категории считывались быстрее.
Как читать график
Длина полосы = количество событий данного типа. Цифра справа = точное значение (count). Цвет = тип бедствия (категориальная кодировка).
Что мы анализировали
Отфильтровали данные по дате: берём только события с 01.01.2023, чтобы исключить неполный 2022 год.
Построили частотное распределение по disaster_type (агрегация groupby/value_counts).
Посчитали суммарное количество событий и долю лидирующего типа.
Ключевой вывод по графику
Распределение по типам выглядит достаточно ровным: значения находятся примерно в диапазоне 2700–2860 событий на тип (за 2023–2025). Лидирующий тип — Землетрясения (около 14–15% всех событий периода). Это важная отправная точка: частота показывает «как часто происходит», но не отвечает на вопрос «насколько разрушительно» — дальше сравним типы по ущербу и severity.
График 3: «Частота vs медианный ущерб по типам происшествий»
Данные и период
Используются события с 2023 года (2022 исключён, так как представлен неполным годом и искажает сравнения по частоте).Что изображено
Каждая точка — один тип природного бедствия (7 типов). Ось X (Frequency) — количество событий данного типа за период (count). Ось Y (Typical Loss) — медианный экономический ущерб одного события данного типа (USD)Используется логарифмическая шкала по Y, потому что ущерб имеет выбросы и широкий диапазон.
Как читать «крест»
Пунктирные линии — медианы по типам:правее вертикальной линии = тип встречается чаще медианного уровня,
выше горизонтальной линии = типичный ущерб выше медианного уровня.
Интерпретация квадрантов
High freq / High loss: типы, которые одновременно распространённые и «дорогие» (приоритетные риски).
High freq / Low loss: частые, но обычно менее затратные.
Low freq / High loss: редкие, но потенциально очень затратные.
Low freq / Low loss: редкие и обычно менее затратные.
Почему медиана
Медиана устойчивее к экстремальным значениям, поэтому лучше отражает «типичную стоимость» события по типу.График 4: «География событий: доли стран (2023–2025)»
Цель визуализации
Показать, в каких странах в датасете концентрируется наибольшее число событий (по частоте), и насколько распределение «сконцентрировано» в топе.Что показано
Кольцевая диаграмма отображает доли событий по странам за период с 2023 года. Чтобы график был читаемым, мы оставляем топ-7 стран по числу событий, а остальные объединяем в категорию Other.Почему так
Круговые диаграммы плохо читаются при большом числе категорий.Описание применения генеративной модели
Использованный ИИ-инструмент OpenAI ChatGPT Модель: GPT-5.2 (reasoning)
Цель применения ИИ
Подготовить шаблоны кода на Pandas/Matplotlib и помочь с исправлением синтаксических ошибок при запуске в Google Colab.
Как именно использовался ИИ (по задачам)
Код и аналитика: генерация черновых ячеек кода для groupby, расчётов метрик (count, median, YoY); адаптация под требование «анализ только с 2023 года».
Отладка: диагностика ошибок исполнения (SyntaxError/неполный ввод) и предложение исправлений.
Методология: объяснение применяемых статистических приёмов (агрегации, медиана vs среднее, лог-шкала, сравнение групп, эффект «низкой базы»).
Роль автора
Выбор датасета и постановка финальных вопросов анализа.
Запуск кода в Colab, проверка результатов, выбор финальных визуализаций.
Интерпретация результатов и финальные формулировки выводов для презентации.
Контроль ограничений датасета (синтетические данные) и корректности сравнений по периодам.



