
Анализ популярных анимационных проектов
Концепция
В качестве своего проекта мной было принято решение воспользоваться датасетом с сайта Kaggle, в котором была приведена информация о 50-и самых популярных анимационных фильмах и сериалах. Как человеку, увлечённому мультипликацией больше, чем любым другим видом кинематографа, мне хотелось проанализировать именно такую базу данных.
Для анализа в своём проекте я использую следующие типы диаграмм:
1. Столбчатая диаграмма 2. Круговая диаграмма 3. Линейный график 4. Гистограмма
Мною были отобраны конкретно эти диаграммы, так как они, по моему мнению, наилучшим образом представляют различия между данными, позволяя сразу понять суть.
(1) Столбчатая диаграмма. Десятка
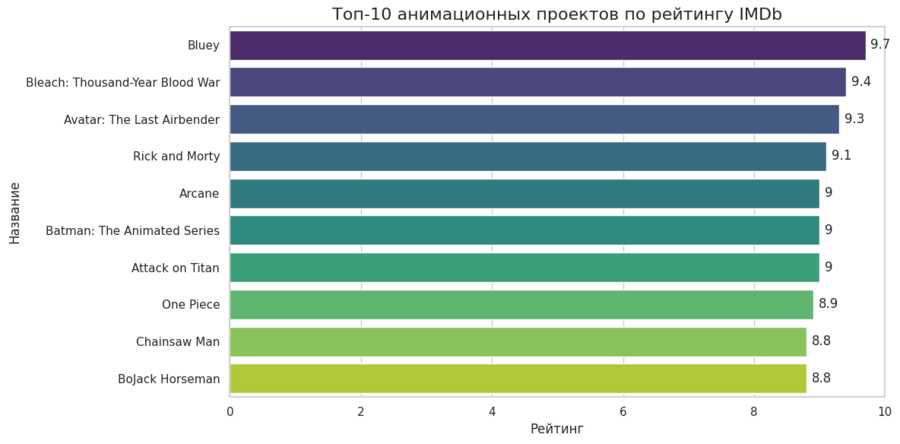
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
df = pd.read_csv ('animation_data.csv')
Выбираю топ-10 проектов, предварительно отсортировав по рейтингу
top_10 = df.dropna (subset=['Rating']).sort_values (by='Rating', ascending=False).head (10)
plt.figure (figsize=(12, 6)) sns.set_theme (style="whitegrid»)
Создаю горизонтальную столбчатую диаграмму (так длинные названия лучше читаются)
plot = sns.barplot ( data=top_10, x='Rating', y='Name', palette='viridis' )
plt.title ('Топ-10 анимационных проектов по рейтингу IMDb', fontsize=16) plt.xlabel ('Рейтинг', fontsize=12) plt.ylabel ('Название', fontsize=12) plt.xlim (0, 10)
for i in plot.containers: plot.bar_label (i, padding=5)
plt.tight_layout () plt.show ()
(2) Круговая диаграмма. Жанры
import pandas as pd import matplotlib.pyplot as plt
df = pd.read_csv ('animation_data.csv')
Разделяю строки с жанрами
all_genres = df['genre'].str.split (', ').explode ().str.strip ()
Подсчитываю количество упоминаний каждого жанра
genre_counts = all_genres.value_counts ()
plt.figure (figsize=(10, 8))
Строю круговую диаграмму
autopct='%1.1f%%' добавляет проценты на график
startangle=140 красиво разворачивает диаграмму
plt.pie ( genre_counts, labels=genre_counts.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Paired.colors )
plt.title ('Распределение жанров в Топ-50 анимационных проектов', fontsize=15) plt.axis ('equal') # Делает круг ровным, а не овальным
plt.tight_layout () plt.show ()
(3) Линейный график. Динамика
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
df = pd.read_csv ('animation_data.csv')
df['Year'] = pd.to_numeric (df['Year'].astype (str).str.extract ('(\d{4})')[0], errors='coerce') df = df.dropna (subset=['Year'])
Группирую данные: считаю количество проектов за каждый год
yearly_counts = df.groupby ('Year').size ().reset_index (name='Count')
plt.figure (figsize=(12, 6)) sns.set_style («whitegrid»)
sns.lineplot ( data=yearly_counts, x='Year', y='Count', marker='o', linewidth=2.5, color='#2c3e50' )
plt.title ('Динамика выпуска топовых анимационных проектов по годам', fontsize=16) plt.xlabel ('Год выпуска', fontsize=12) plt.ylabel ('Количество проектов', fontsize=12)
plt.xticks (rotation=45)
plt.tight_layout () plt.show ()
(1) Гистограмма. Рейтинг
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt
df = pd.read_csv ('animation_data.csv')
df['Rating'] = pd.to_numeric (df['Rating'], errors='coerce') ratings = df['Rating'].dropna ()
plt.figure (figsize=(10, 6)) sns.set_theme (style="white»)
sns.histplot ( ratings, bins=15, kde=True, color='skyblue', edgecolor='black' )
plt.title ('Распределение рейтингов IMDb среди топ-50 проектов', fontsize=16) plt.xlabel ('Рейтинг IMDb', fontsize=12) plt.ylabel ('Частота (Количество проектов)', fontsize=12)
plt.axvline (ratings.mean (), color='red', linestyle='--', label=f’Средний: {ratings.mean ():.2f}') plt.legend ()
plt.tight_layout () plt.show ()
Итог
В процессе анализа информации о 50-и самых популярных анимационных проектах, у меня получилось разработать четыре графика, которые наглядно показывают, как различные аспекты влияют на популярность мультипликационного кино.
Описание применения генеративной модели
В моей работе использовалась такая генеративная модель, как Gemini. Этот инструмент помог мне проверить написанныый код на ошибки и, в случае их обнаружения, всё исправить.
Ссылка на модель: https://gemini.google.com/



