Анализ успеваемости студентов (Student Performance)
Описание датасета
В рамках данного проекта был использован датасет StudentPerformance.csv, содержащий информацию об учебной активности и результатах студентов. Данные включают количество часов, затрачиваемых на обучение, предыдущие академические результаты, продолжительность сна, участие во внеучебных активностях, количество решённых тренировочных заданий, а также интегральный показатель успеваемости (Performance Index).
Датасет не содержит критических пропусков в ключевых числовых переменных, что позволяет проводить анализ без сложной предварительной очистки данных.
Цель исследования
Целью исследования является выявление факторов, связанных с академической успеваемостью студентов, а также анализ взаимосвязей между учебными привычками, предыдущими результатами и итоговым уровнем performance.
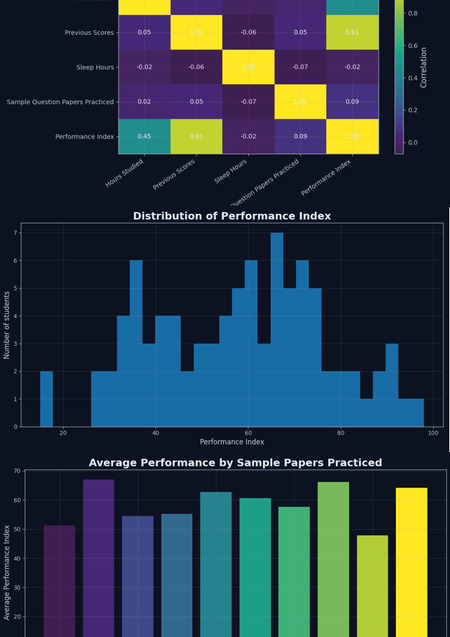
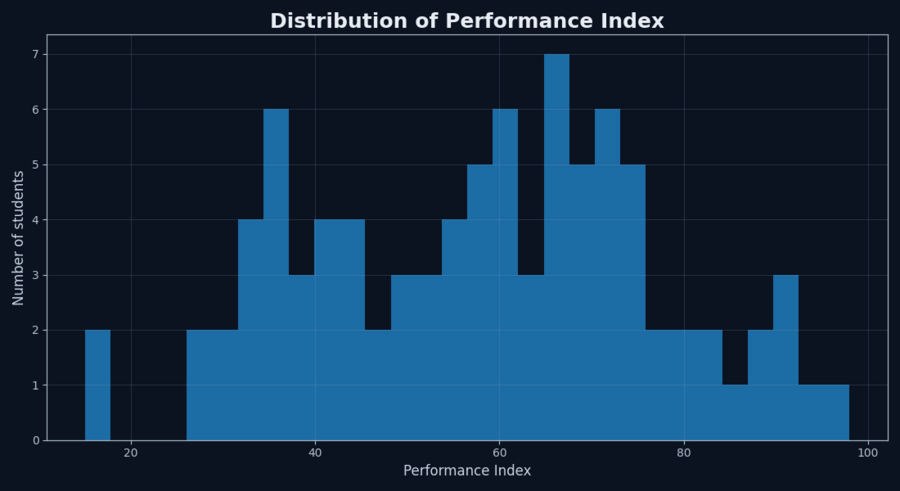
Распределение показателя успеваемости
На гистограмме представлено распределение значений Performance Index. Видно, что основная часть студентов сосредоточена в среднем диапазоне значений, в то время как экстремально низкие и экстремально высокие показатели встречаются значительно реже. Такое распределение характерно для образовательных данных и указывает на наличие «среднего уровня» успеваемости у большинства студентов.
Корреляционная матрица числовых признаков
Корреляционная матрица демонстрирует взаимосвязи между числовыми переменными датасета. Наиболее заметная положительная корреляция наблюдается между Previous Scores и Performance Index, что логично отражает влияние предыдущих академических результатов на текущую успеваемость. Остальные переменные (часы обучения, сон, количество тренировочных заданий) показывают более умеренные связи.
Зависимость успеваемости от времени обучения
Точечная диаграмма иллюстрирует связь между количеством часов, затраченных на обучение, и итоговым показателем успеваемости. В целом прослеживается положительная тенденция: при увеличении времени обучения средний уровень Performance Index возрастает, однако наблюдается значительный разброс значений, что указывает на влияние дополнительных факторов.
Влияние предыдущих оценок на текущую успеваемость
На данном графике показана связь между предыдущими академическими результатами студентов и их текущей успеваемостью. Тренд выражен более чётко, чем в случае с часами обучения: студенты с более высокими предыдущими оценками, как правило, демонстрируют более высокий Performance Index.
Продолжительность сна и успеваемость
Диаграмма рассеяния с добавленной линейной линией тренда отражает зависимость между количеством часов сна и уровнем успеваемости. Связь носит умеренный характер: оптимальный уровень сна ассоциируется с более стабильными результатами, однако сам по себе сон не является определяющим фактором успеваемости.
Участие во внеучебных активностях и успеваемость
Boxplot по категориям участия во внеучебных активностях (Yes / No) показывает различия в распределении Performance Index. В среднем студенты, участвующие во внеучебных активностях, демонстрируют сопоставимые или немного более высокие результаты, что может указывать на положительный эффект сбалансированного учебного и внеучебного опыта.
Количество решённых тренировочных заданий и средняя успеваемость
Столбчатая диаграмма средних значений Performance Index в зависимости от количества решённых тренировочных заданий показывает устойчивую положительную динамику. Увеличение практики, как правило, связано с ростом среднего уровня успеваемости, что подтверждает важность регулярной самостоятельной работы.
Заключение
В ходе анализа были выявлены следующие ключевые закономерности:
- Успеваемость студентов имеет выраженное распределение со смещением в средний диапазон.
- Предыдущие академические результаты являются одним из наиболее сильных факторов, связанных с текущей успеваемостью.
- Поведенческие характеристики, такие как время обучения, практика и режим сна, оказывают влияние на результаты, однако не являются единственными определяющими факторами.
Визуальный анализ позволил наглядно продемонстрировать основные зависимости и подтвердить, что комплексный подход к обучению (практика, базовая подготовка, режим) связан с более высокими академическими результатами.
Использование ИИ
В рамках проекта генеративная модель ChatGPT (OpenAI) использовалась в качестве вспомогательного инструмента для:
- структурирования аналитической части исследования;
- формулировки описаний визуализаций;
- подготовки итоговых выводов.
ИИ не заменял самостоятельный анализ данных и использовался исключительно для поддержки аналитической и текстовой работы.
Блокнот с кодом
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib as mpl
=========================
STYLE (ACADEMIC / EDUCATION)
=========================
plt.rcParams.update ({ «figure.figsize»: (11, 6), «figure.facecolor»: «#0B1220», «axes.facecolor»: «#0B1220», «axes.titlesize»: 18, «axes.titleweight»: «bold», «axes.labelsize»: 12, «xtick.labelsize»: 10, «ytick.labelsize»: 10, «axes.grid»: True, «grid.alpha»: 0.18, «grid.color»: «#9FB4C7», «axes.edgecolor»: «#A7B6C2», «axes.linewidth»: 0.9, «text.color»: «#E8EEF4», «axes.titlecolor»: «#E8EEF4», «axes.labelcolor»: «#C9D6E3», «xtick.color»: «#B7C4D1», «ytick.color»: «#B7C4D1», «font.family»: «DejaVu Sans» })
Палитра под «education / analytics»
ACCENT = «
7BD389»
зелёный акцент ACCENT2 = «2D6CDF»
синий акцент WARN = «FFD166»
жёлтый DANGER = «E63946»
красный NEUTRAL = «6C757D»
серыйCMAP = mpl.cm.get_cmap («viridis»)
=========================
LOAD DATA
=========================
df = pd.read_csv («StudentPerformance.csv»)
=========================
BASIC CLEANING
=========================
Убедимся, что ключевые столбцы числовые
num_cols = [ «Hours Studied», «Previous Scores», «Sleep Hours», «Sample Question Papers Practiced», «Performance Index» ] for c in num_cols: df[c] = pd.to_numeric (df[c], errors="coerce»)
df[«Extracurricular Activities»] = df[«Extracurricular Activities»].astype (str).str.strip ()
df = df.dropna (subset=num_cols).copy ()
df = df.query (
«Hours Studied >= 0 and Sleep Hours >= 0 and "
«Previous Scores >= 0 and Sample Question Papers Practiced >= 0 and "
«Performance Index >= 0»
).copy ()
=========================
QUICK STATS
=========================
print («Rows:», len (df)) print («Extracurricular counts:\n», df[«Extracurricular Activities»].value_counts ()) print («\nPerformance Index summary:\n», df[«Performance Index»].describe ())
=========================
1) DISTRIBUTION OF PERFORMANCE (HIST)
=========================
plt.figure () vals = df[«Performance Index»].values plt.hist (vals, bins=30, alpha=0.9) plt.title («Distribution of Performance Index») plt.xlabel («Performance Index») plt.ylabel («Number of students») plt.tight_layout () plt.show ()
=========================
2) CORRELATION HEATMAP (NUMERIC)
=========================
plt.figure (figsize=(10, 6)) corr = df[num_cols].corr (numeric_only=True)
im = plt.imshow (corr.values, interpolation="nearest», aspect="auto», cmap=CMAP) plt.title («Correlation Matrix (Numeric Features)») plt.xticks (range (len (num_cols)), num_cols, rotation=35, ha="right») plt.yticks (range (len (num_cols)), num_cols)
cbar = plt.colorbar (im) cbar.set_label («Correlation»)
for i in range (corr.shape[0]): for j in range (corr.shape[1]): plt.text (j, i, f"{corr.values[i, j]:.2f}», ha="center», va="center»)
plt.tight_layout () plt.show ()
=========================
3) HOURS STUDIED vs PERFORMANCE (SCATTER)
=========================
plt.figure ()
сэмпл для читаемости (если нужно)
sample = df.sample (min (5000, len (df)), random_state=42)
plt.scatter ( sample[«Hours Studied»], sample[«Performance Index»], alpha=0.35, s=18 ) plt.title («Hours Studied vs Performance Index») plt.xlabel («Hours Studied») plt.ylabel («Performance Index») plt.tight_layout () plt.show ()
=========================
4) PREVIOUS SCORES vs PERFORMANCE (SCATTER)
=========================
plt.figure () sample2 = df.sample (min (5000, len (df)), random_state=7)
plt.scatter ( sample2[«Previous Scores»], sample2[«Performance Index»], alpha=0.35, s=18 ) plt.title («Previous Scores vs Performance Index») plt.xlabel («Previous Scores») plt.ylabel («Performance Index») plt.tight_layout () plt.show ()
=========================
5) SLEEP HOURS vs PERFORMANCE (SCATTER + TREND)
=========================
plt.figure () x = df[«Sleep Hours»].values y = df[«Performance Index»].values
plt.scatter (x, y, alpha=0.30, s=16)
coef = np.polyfit (x, y, 1) xs = np.linspace (np.min (x), np.max (x), 200) ys = coef[0] * xs + coef[1] plt.plot (xs, ys, linewidth=2)
plt.title («Sleep Hours vs Performance Index») plt.xlabel («Sleep Hours») plt.ylabel («Performance Index») plt.tight_layout () plt.show ()
=========================
6) EXTRACURRICULAR ACTIVITIES vs PERFORMANCE (BOX)
=========================
plt.figure () groups = [«No», «Yes»] data = [df.loc[df[«Extracurricular Activities»] == g, «Performance Index»].values for g in groups]
bp = plt.boxplot (data, labels=groups, patch_artist=True, widths=0.55)
раскраска боксплота
colors = [NEUTRAL, ACCENT] for patch, col in zip (bp[«boxes»], colors): patch.set_facecolor (col) patch.set_alpha (0.55)
for part in [«whiskers», «caps», «medians»]: for item in bp[part]: item.set_color (»#D6E0EA»)
plt.title («Performance Index by Extracurricular Activities») plt.xlabel («Extracurricular Activities») plt.ylabel («Performance Index») plt.tight_layout () plt.show ()
=========================
7) SAMPLE PAPERS PRACTICED vs PERFORMANCE (MEAN BAR)
=========================
plt.figure (figsize=(11, 6)) grp = df.groupby («Sample Question Papers Practiced»)[«Performance Index»].mean ().sort_index ()
x = grp.index.values y = grp.values
градиент по уровню практики
cols = [CMAP (i / (len (x)-1 if len (x) > 1 else 1)) for i in range (len (x))] plt.bar (x, y, color=cols)
plt.title («Average Performance by Sample Papers Practiced») plt.xlabel («Sample Question Papers Practiced») plt.ylabel («Average Performance Index») plt.tight_layout () plt.show ()
Датасет



