
Евровидение: анализ положения конкурса в массовой культуре
Введение: выбор анализа платформы.

В работе использован открытый датасет Spijkervet / Eurovision Song Contest Dataset с GitHub, содержащий CSV-данные об участниках, результатах и голосовании конкурса за 1956–2023 годы. Он был выбран как надёжный и воспроизводимый источник для анализа «Евровидения» в долгосрочной перспективе.
Я смотрю Евровидение с 2012 года и, пользуясь многолетним опытом, показалось, что взятые данные позволяют сопоставлять успех песен с механизмами его формирования — голосованием жюри и зрителей, а также международной структурой поддержки. Творчество всегда сложно оценивать, но эти объективные цифровые данные могут служить хорошим подспорьем для формирования аналитической базы.
Почему именно этот датасет?
Датасет Spijkervet/eurovision-dataset даёт структурированное описание «Евровидения» как института массовой культуры: он охватывает 1956–2023 и включает метаданные заявок (страна, исполнитель, песня), результаты по раундам (полуфиналы/финал) и подробные данные голосования «страна → страна»; для 2015–2023 добавлен слой букмекерских коэффициентов. Для анализа использованы линейные и столбчатые диаграммы, поскольку они наглядно показывают динамику и различия между странами и периодами, а также простые сетевые графики для визуализации межстранового голосования.

ChatGPT. Prompt: Hyper-realistic wide shot of a Eurovision arena in the distance, massive crowd, colorful stage lights, international flags, cinematic atmosphere, 16:9.

Из базы можно извлечь три класса аналитически значимых знаний. Во-первых, по contestants.csv — измерять успех песни (место, очки), фактор экспозиции (порядок выступления) и, для современной эпохи, расхождение между оценкой жюри и телезрителей как различие между институциональным и массовым вкусом; дополнительно доступны тексты песен и ссылки на YouTube, что позволяет делать корпусный анализ тематик и сопоставлять его с результатами. Во-вторых, по votes.csv — реконструировать географию культурных предпочтений как сеть голосования, выявляя устойчивые пары, кластеры и асимметрии поддержки между странами и их динамику по годам. В-третьих, по betting_offices.csv — сравнивать ожидания публичного рынка с итогом и фиксировать случаи, когда конкурс подтверждает заранее сложившуюся популярность, либо производит «сюрприз», потенциально меняющий траекторию внимания к песне.
Данные были загружены из CSV (contestants.csv и votes.csv), затем приведены к единому формату: нормализованы названия стран, проверены пропуски, удалены дубликаты, а типы полей (год, очки, места) приведены к числовым. Далее были собраны производные таблицы: динамика по годам (число участников, средние очки), сравнения по странам (сумма/среднее очков, доля выходов в финал) и матрица межстранового голосования (агрегация «кто кому сколько дал»).
Графики стилизовались в нейтральной инфографической манере: единый шрифт, одинаковая толщина линий, аккуратная сетка, подписи осей и единая система заголовков. В качестве ориентира использовались типовые решения академической визуализации (минимум декоративности, максимум читаемости), без имитации конкретного брендинга.
Формат визуализации выбран в его наиболее логичном виде: каждый график отвечает на один вопрос и сопровождается короткой интерпретацией (что измеряется, что видно, какой вывод).
Применённые методы: описательная статистика (суммы, средние, медианы, доли), сравнение распределений, анализ динамики во времени, а для голосования — базовые сетевые метрики (входящая/исходящая сила как сумма полученных/отданных очков) и визуализация направленного графа.
Визуал графических систем.
Палетка основных цветов.
#220f43 — фон: поле графика, высокий контраст с светлыми элементами, снижает визуальный шум, позволяет «подсветить» данные акцентом.
#000000 — структура: оси/деления/подписи, нейтральность и читаемость, задаёт иерархию и «скелет» графика (на тёмном фоне — использовать как логическую роль, но визуально через светлый тон/серый).
#ff631a — акцент: данные/выделения, максимальная заметность на фоне, подходит для ключевой серии, пиков, маркеров, аннотаций; требует экономного применения, чтобы не перегрузить композицию.
#1f77b4 — второй базовый цвет, появляющийся в графике. Для контраста и насыщения.
Шрифт: Liberation Sans
mpl.rcParams[«font.family»] = «Liberation Sans» mpl.rcParams[«axes.titlesize»] = 14 mpl.rcParams[«axes.labelsize»] = 11 mpl.rcParams[«xtick.labelsize»] = 10 mpl.rcParams[«ytick.labelsize»] = 10
Количественный успех стран в конкурсе (топ-15).

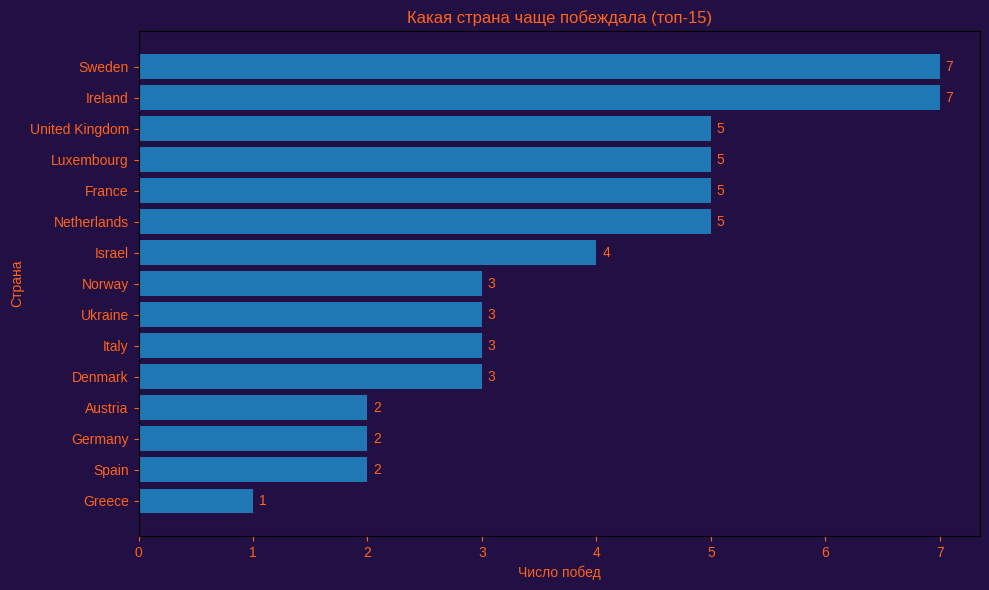

Построена горизонтальная столбчатая диаграмма топ-15 стран по числу побед (победитель = place_contest == 1). Визуализация удачна для ранжирования: длинные названия читаются, значения подписаны, сразу видны лидеры (Sweden и Ireland — по 7) и группы равных результатов (несколько стран по 5 и по 3).
Используемые статистические методы и приёмы визуализации:
(1) фильтрация победителей по условию place_contest = 1; (2) частотный подсчёт побед по странам (groupby + size); (3) ранжирование и усечение распределения до top-N; (4) аннотирование значений на столбцах для точного считывания; (5) (имплицитно) обработка «совместных побед» как множественных наблюдений.
Для реализации кода и создания графика был выбран Google Colab. Табличные данные подгружались в формате SVC, считывались при помощи конструкции pd.read_csv ().
import os import pandas as pd import matplotlib.pyplot as plt from urllib.request import urlretrieve
Анализ частоты побед по странам показывает наличие ограниченного круга «символически привилегированных» участников. Такие страны, как Швеция, Ирландия, Великобритания, Люксембург и Франция, накапливают победы на протяжении десятилетий, что указывает на структурную асимметрию в культурном капитале внутри конкурса. Однако это доминирование не превращается в линейную гегемонию: разрывы между лидерами и остальными странами остаются относительно невелики, а распределение побед не концентрируется в одной точке.
Фактор голосования, в том числе «соседского».

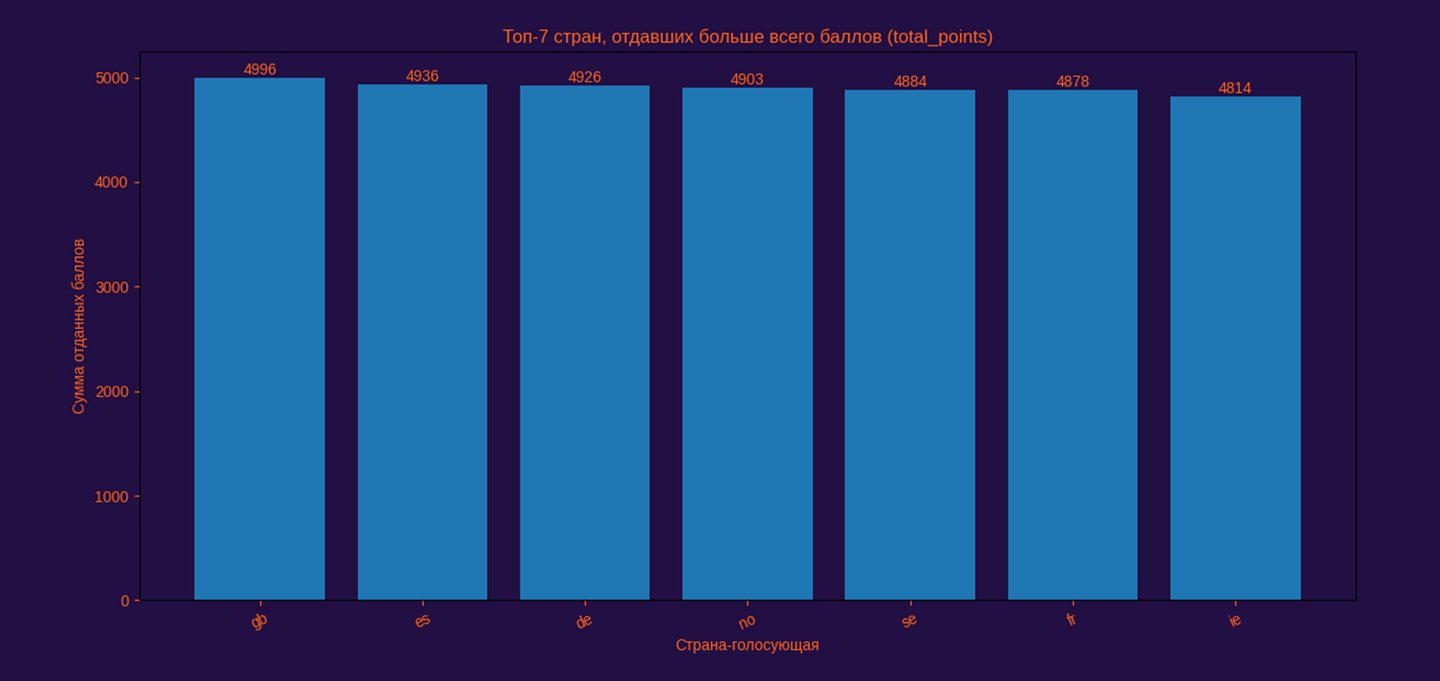
Сначала я подгружаю данные напрямую по URL (pd.read_csv (url)), чтобы код не зависел от локальных файлов и всегда работал воспроизводимо. Саму таблицу с исходными данными прикрепляю ссылкой. Затем фиксирую визуальный стиль — задаю Liberation Sans и цветовую палитру через глобальные настройки matplotlib, чтобы все элементы графика были единообразны.
Далее выбираю аналитическую метрику total_points и агрегирую данные: группирую голоса по стране-источнику и суммирую их (groupby («from_country»).sum ()), после чего сортирую результат и оставляю топ-7 значений. Это формализует вопрос о странах, которые суммарно отдали больше всего баллов.
На финальном этапе строю столбчатую гистограмму (ax.bar), поскольку сравниваются агрегированные категории, а не распределение. Подписи значений добавляются поверх столбцов, чтобы визуализация была интерпретируемой без обращения к шкале.
import os import pandas as pd import matplotlib.pyplot as plt from urllib.request import urlretrieve
Анализ выявляет активное участие одних и тех же государств в поддержании конкурсной экосистемы. Это указывает на Евровидение как на устойчивую транснациональную коммуникационную сеть, где важна не только победа, но и постоянное вовлечение в ритуал голосования и взаимного признания.
«Большая пятерка» стран-основательниц и их положение в общем процессе истории конкурса.
ChatGPT. The typical French Eurovision performance

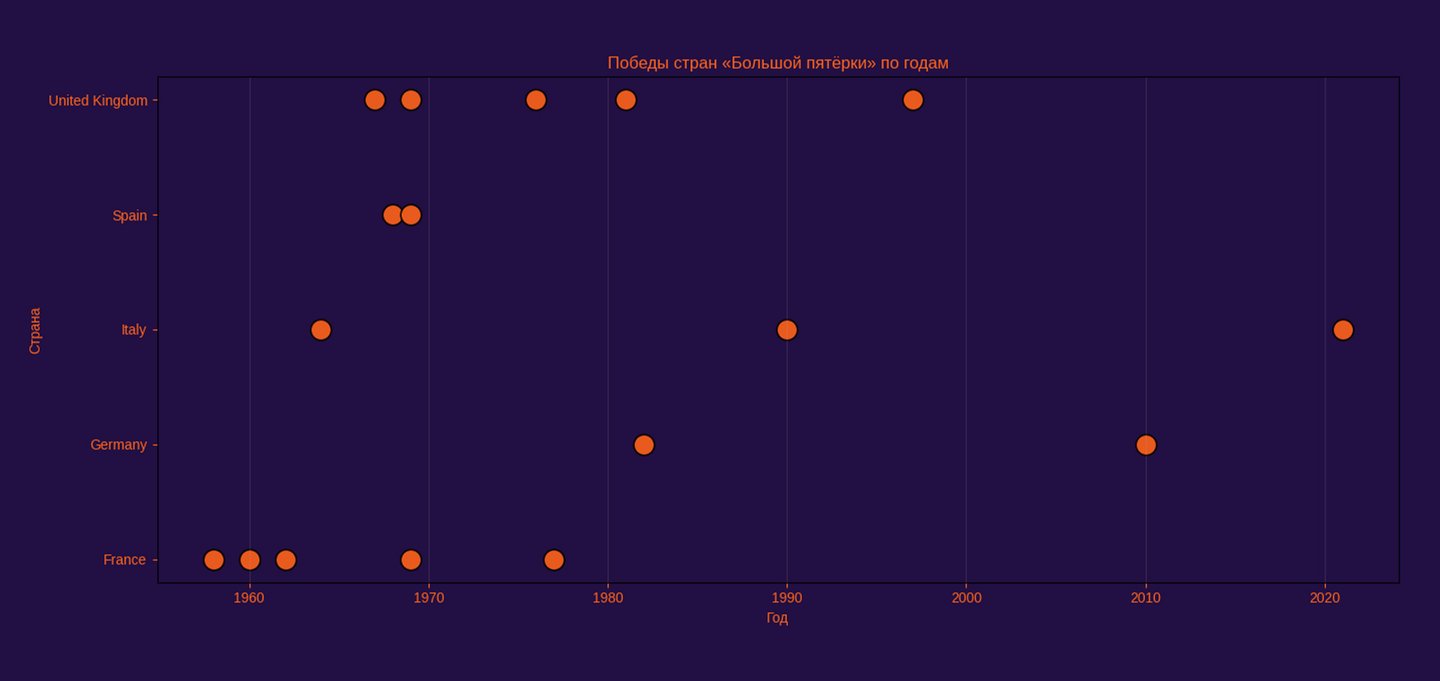

С помощью пузырьковой диаграммы демонстрирую количество побед стран, зачинавших конкурс. Информация представляет собой фактор взаимосвязи «высокого» положения стран и их успеха на конкурсе.
Данные предварительно отфильтрованы по условию place_contest == 1, что формализует бинарное событие «победа»; далее оставлены только уникальные пары (country, year) с помощью drop_duplicates ([country, year]), что предотвращает искусственное дублирование пузырей в годы с несколькими записями.
import os import pandas as pd import matplotlib.pyplot as plt from urllib.request import urlretrieve
Для выбранных 12 стран считаются показатели:
mean_place — среднее итоговое место wins — число побед participations — число участий years_since_debut — лет с дебюта top10_share — доля попаданий в топ-10
Временная визуализация побед стран «Большой пятёрки» показывает разорванность исторической траектории успеха. Победы распределены неравномерно, с большими временными промежутками, что подчёркивает эпизодический характер символического признания. Евровидение в этом смысле не поощряет постоянство, а работает через редкие, но яркие события, которые затем надолго закрепляются в культурной памяти.
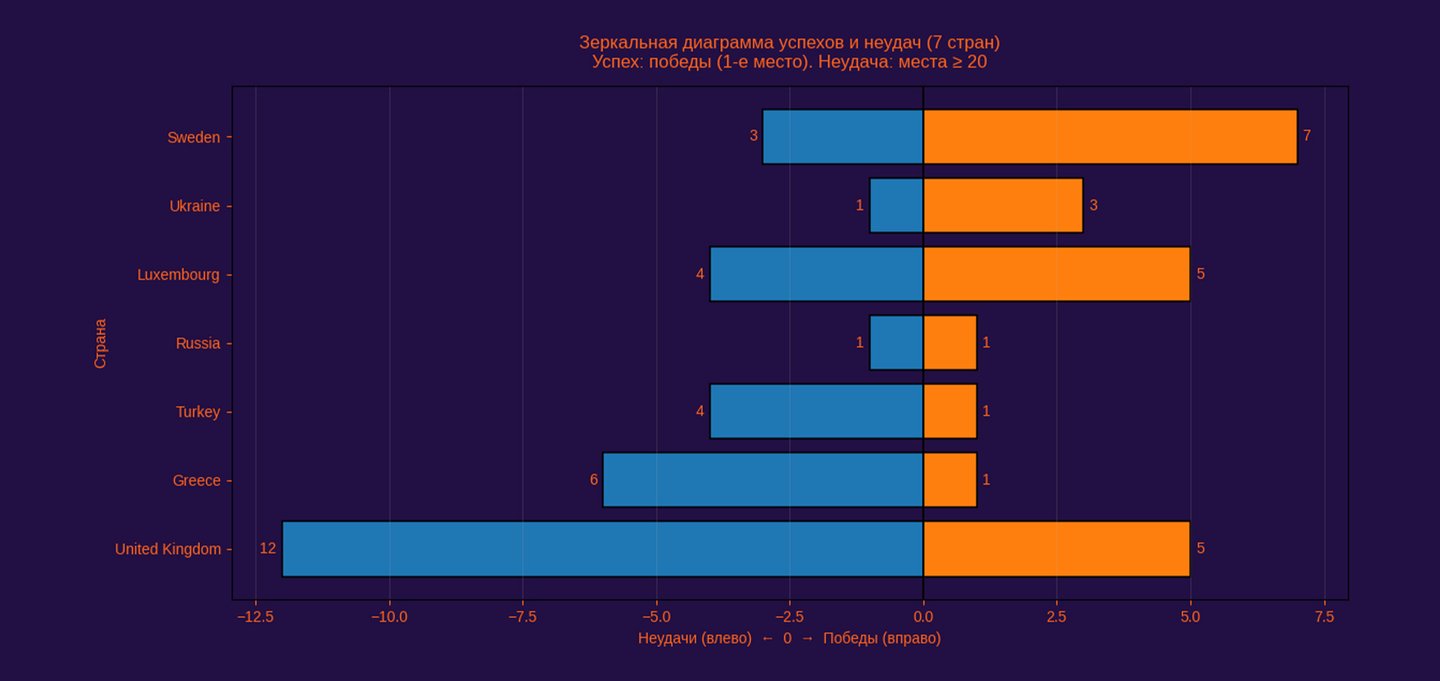
«Удачи» и «неудачи» на конкурсе: анализ стран из разных частей Европы. Выявление тенденции или ее опровержение.


import os import pandas as pd import matplotlib.pyplot as plt from urllib.request import urlretrieve
График представляет «зеркальное» сравнение успехов и неудач выбранных семи стран на Евровидении. Правая (положительная) часть показывает количество побед (1-е места), то есть эпизоды максимального символического признания в конкурсной системе. Левая (отрицательная) часть показывает количество «низших» результатов (в коде — места не выше порога place_contest ≥ 20), то есть эпизоды провала или периферийного присутствия в рейтинге. Визуально это даёт профиль каждой страны как баланс между пиками культурной видимости и зонами слабой результативности.
Во-первых, событие «успех» формализовано строго как place_contest == 1, а «неудача» — как place_contest >= LOW_PLACE_THRESHOLD, где порог задаётся параметром LOW_PLACE_THRESHOLD = 20 и может быть изменён. Во-вторых, зеркальность достигается тем, что значения «неудач» умножаются на минус при построении (-low_places), поэтому они уходят влево от нуля, а «победы» — вправо. В-третьих, добавлена центральная опорная линия axvline (0), которая делает сравнение симметричным и метрически считываемым. В-четвёртых, страны отсортированы по индексу баланса wins — low_places, поэтому порядок строк не случайный: он усиливает интерпретацию «у кого профиль скорее успешный, а у кого — скорее неудачный».
Зеркальная диаграмма успехов и неудач демонстрирует принципиальную двойственность конкурсного статуса. Даже страны с высоким числом побед обладают сопоставимым объёмом «неудачных» результатов (низкие места), тогда как некоторые участники с редкими победами демонстрируют более стабильное срединное присутствие. Это подтверждает, что Евровидение не функционирует как классическая рейтинговая система накопления: каждый год конкурс в значительной степени «обнуляет» прошлые достижения.
ChatGPT. The typical Italian performance
В работе я использовал ChatGPT как вспомогательный аналитический и технический инструмент. С его помощью уточнял структуру датасетов, формулировал исследовательские гипотезы, подбирал типы визуализаций и проверял корректность Python-кода для построения графиков. Нейронка выступала инструментом для ускорения работы с данными и визуальной аналитикой. Иллюстрации в проекте, отражающие шаблонное представление о визуале конкурса, и обложка проекта сделаны в этой же нейросети.
Промпт для обложки: A hyper-realistic Eurovision stage performance: a charismatic long-haired male singer standing confidently at the center of a futuristic circular stage, surrounded by sleek metallic and chrome decorations, glowing blue and white light structures, dramatic spotlights, and a massive cheering audience. Minimalist yet powerful performance, high-end concert lighting, cinematic atmosphere, ultra-detailed, realistic textures, epic scale.
Евровидение в массовой культуре выступает не как соревнование с предсказуемой иерархией, а как ритуализированное медиасобытие, в котором символический капитал распределяется циклически и фрагментарно. Его социальная значимость заключается не в стабильном определении «лучших», а в регулярном производстве моментов коллективного внимания, национальной репрезентации и культурного соперничества, каждый раз заново переопределяющих статус участников.



