
О чём чаще всего говорится в Библии: анализ тем и структуры текст
О проекте
В этом проекте я исследую текст Библии как массив данных и пытаюсь понять, какие темы, слова и образы оказываются наиболее значимыми, а также как меняется структура текста в зависимости от контекста.
В качестве основного источника данных был выбран текст Библии в переводе King James Version (KJV) — один из самых распространённых и цитируемых английских переводов. Данные были взяты из открытого датасета Kaggle и представлены в табличном формате (CSV).
Библия — это не только религиозный текст, но и сложный корпус, который формировался на протяжении веков и содержит большое количество повторяющихся структур, устойчивых формулировок и смысловых акцентов.
Используя методы анализа данных, интересно посмотреть:
— какие слова и темы встречаются чаще всего, — чем различаются Ветхий и Новый Заветы, — как меняется форма стиха в зависимости от смысловой нагрузки.
В проекте я использую четыре визуализации:
1. Горизонтальная столбчатая диаграмма значимых слов. Показывает, какие слова чаще всего встречаются в тексте Библии после очистки от служебной лексики. Позволяет увидеть основные лексические и смысловые опоры текста.
2. Столбчатая диаграмма ключевых тем Ветхого и Нового Заветов. Сравнивает частоту употребления выбранных ключевых слов (god, lord, law, fear, love) в Ветхом и Новом Заветах. Демонстрирует различия в смысловых акцентах между двумя частями Библии.
3. Круговая диаграмма упоминаний Лиц Троицы. Показывает, как распределяются упоминания Бога Отца, Иисуса Христа и Святого Духа в тексте Библии. Визуализация помогает увидеть относительное соотношение этих образов.
4. Boxplot длины стиха в зависимости от числа упоминаний Бога. Отражает, как меняется длина стиха (в количестве слов) при разном числе упоминаний Бога, а также позволяет сравнить распределения для Ветхого и Нового Заветов.

Пошаговый план работы
Сначала я подключила основные библиотеки для анализа и визуализации данных: pandas — для работы с таблицами, re — для очистки текста, matplotlib и seaborn — для построения графиков. После этого я загрузила датасет с текстом Библии в формате CSV и вывела первые строки таблицы, чтобы убедиться, что файл прочитался корректно.
В исходном датасете названия столбцов представлены в сокращённом виде. Для удобства дальнейшей работы я переименовала их в более понятные и читаемые названия: номер книги, главы, стиха и сам текст.
Чтобы анализировать текст как данные, я привела весь текст к нижнему регистру и удалила знаки препинания и лишние символы. Это позволяет корректно считать слова и сравнивать их между собой.
После очистки текста я разбила каждый стих на список отдельных слов. Так текст Библии стал массивом данных, с которым можно выполнять количественный анализ.
Перед построением графиков я задала единый визуальный стиль проекта. Мне было важно, чтобы все визуализации выглядели как части одного исследования, поэтому я заранее определила цветовую палитру и общие настройки оформления.
Единый визуальный стиль помогает воспринимать проект как целостную исследовательскую работу, а не набор отдельных графиков.
Визуализация данных

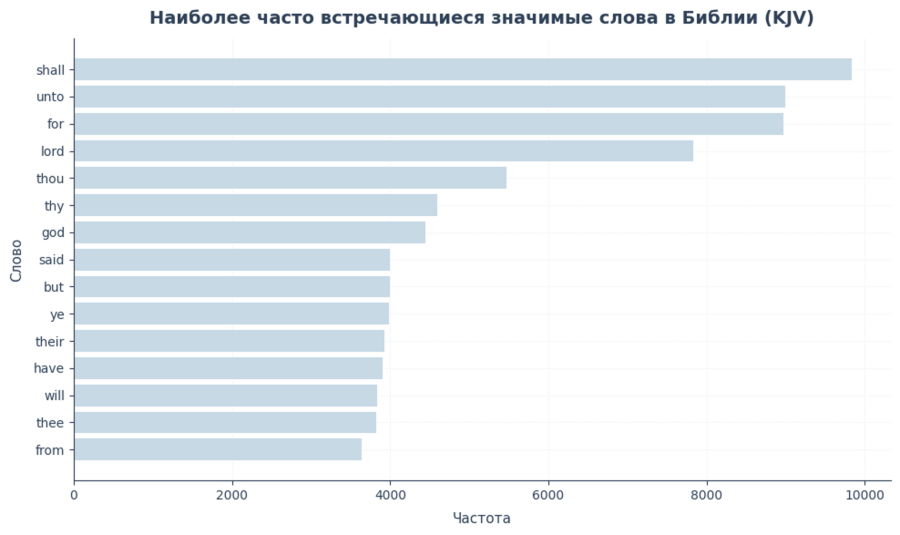

В первом графике я ищу ответ на вопрос: из каких слов вообще состоит текст Библии и какие из них встречаются чаще всего. Для этого я разбиваю каждый стих на отдельные слова, объединяю их в один массив и считаю частоту каждого слова во всём корпусе текста.
Затем я отбираю самые часто встречающиеся слова и визуализирую их в виде горизонтальной столбчатой диаграммы. Такой формат удобен для сравнения: сразу видно, какие слова доминируют, а какие находятся на периферии.
По этому графику хорошо видно, что текст Библии во многом строится вокруг служебных и повторяющихся формулировок, а также ключевых религиозных понятий. Это задаёт основу для дальнейшего анализа: прежде чем говорить о смыслах, важно понять, какой языковой «фон» у текста в целом.


Дальше я перехожу от общего частотного анализа к сравнению смыслов и задаю следующий вопрос: одинаковые ли темы важны для Ветхого и Нового Заветов, или акценты между ними смещаются?
Для этого я выбираю несколько тематически значимых слов (например, god, lord, law, love, fear) и считаю, как часто каждое из них встречается в Ветхом и Новом Заветах отдельно. Результат я показываю в виде столбчатой диаграммы с разбиением по Заветам.
Этот график позволяет увидеть различие смысловых фокусов: какие темы сильнее связаны с Ветхим Заветом, а какие с Новым. Так, текст начинает читаться не просто как единое целое, а как две связанные, но разные по настроению и содержанию части.


На следующем этапе мне становится интересно посмотреть не просто на слова, а на образы, которые формируют религиозное содержание текста. Здесь я задаю вопрос: какие Лица Троицы упоминаются чаще всего и в каких пропорциях?
Для этого я группирую слова, связанные с Богом Отцом, Иисусом Христом и Святым Духом, и суммирую количество их упоминаний во всём тексте. Затем я превращаю эти данные в круговую диаграмму, где каждый сектор — это доля одного образа.
Этот график хорошо работает именно в круговом формате, потому что он показывает соотношение, а не абсолютные значения. По нему сразу видно, какой образ доминирует в тексте и как распределяется внимание между различными божественными фигурами.

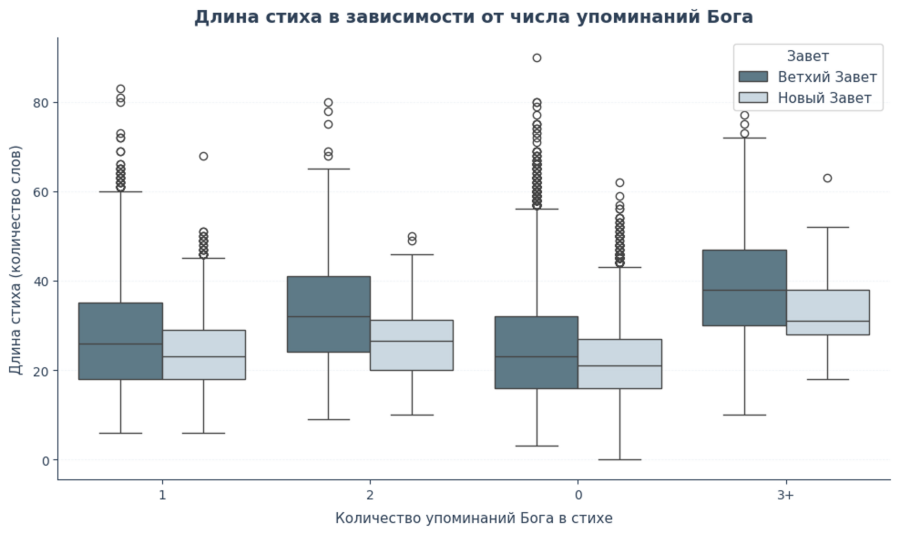

В последнем графике я связываю смысл и форму текста. Здесь меня интересует вопрос: меняется ли структура стиха в зависимости от того, насколько он «насыщен» упоминаниями Бога.
Для каждого стиха я считаю, сколько раз в нём встречаются слова god и lord, а также определяю длину стиха — количество слов. Затем я группирую стихи по числу упоминаний Бога (0, 1, 2 и 3+) и сравниваю распределения длин стихов отдельно для Ветхого и Нового Заветов с помощью boxplot.
Этот график позволяет увидеть не отдельные примеры, а общую тенденцию: как меняется форма стиха при росте смысловой концентрации. В результате текст Библии начинает восприниматься не только как духовное содержание, но и как структурно организованный литературный корпус, где форма и смысл тесно связаны.
Заключение
В этом проекте я рассматривала текст Библии как корпус данных, внутри которого можно выявлять повторяющиеся структуры, ключевые слова и различия между Ветхим и Новым Заветами. Используя методы анализа данных и визуализации, я попыталась понять, какие темы оказываются наиболее значимыми и как меняется структура стихов в зависимости от контекста.
Анализ частотных слов показал доминирование обращений, повелительных форм и слов, связанных с Богом, что подчёркивает нормативный и риторический характер текста. Сравнение ключевых тем Ветхого и Нового Заветов выявило различие акцентов: в Ветхом Завете чаще встречаются слова, связанные с законом и властью, тогда как в Новом больше внимания уделяется личным отношениям и любви.
Круговая диаграмма упоминаний Лиц Троицы показала явное преобладание обращений к Богу Отцу при заметной, но меньшей доле упоминаний Иисуса Христа и Святого Духа. Анализ длины стихов дополнил картину: стихи с большим числом упоминаний Бога в среднем оказываются длиннее, особенно в Ветхом Завете.
В целом проект демонстрирует, что количественный анализ позволяет по-новому взглянуть на хорошо известный текст, выявляя общие закономерности, которые трудно заметить при традиционном чтении.
Обложка
Обложка проекта была сгенерирована в ChatGPT промт: An abstract, ethereal illustration of the Holy Trinity. Three softly glowing figures emerging from darkness: God the Father and Jesus Christ represented as tall, luminous human silhouettes with gentle halos, and the Holy Spirit as a radiant dove of light between them. The figures are intentionally blurred and partially dissolved, especially toward the legs, creating a floating, weightless feeling. Soft painterly textures, heavy blur, and glowing light effects. Calm, spiritual, and minimalistic mood. Color palette limited to deep navy blue (304258), muted blue-gray (577C8E), pale blue (C7D9E5), and soft white (FFFFFF). No sharp details, no realistic faces, dreamlike abstraction, sacred atmosphere, smooth gradients, digital painting style.
Использованные инструменты
Kaggle Данные для проекта были взяты с Kaggle — это датасет с текстом Библии в переводе King James Version (KJV) в формате CSV. Он содержит стихи с разбивкой по книгам и главам, что удобно для анализа.
Google Colab Облачная среда для анализа данных. В Google Colab я загружала датасет, выполняла код, проводила обработку текста и строила визуализации, а также сохраняла итоговые графики.
Pandas Основной инструмент для работы с данными. Использовался для загрузки CSV-файла (read_csv), очистки и подготовки текста, создания новых признаков (длина стиха, количество упоминаний Бога, группировки по Заветам), а также для агрегаций и подсчётов частот (value_counts, groupby), необходимых для визуализаций.
NumPy Применялся для базовых числовых операций и поддержки вычислений: работы с массивами, расчёта статистик и подготовки данных для группировки и сравнения.
Matplotlib Использовался для построения всех визуализаций проекта. С его помощью был задан единый визуальный стиль: собственная цветовая палитра, единое оформление подписей осей, заголовков и легенд, а также сохранение графиков в высоком разрешении.
ChatGPT Использовался как вспомогательный инструмент для проверки логики анализа, уточнения кода, подбора форматов визуализаций и формулировки текстовых пояснений и выводов. А также для генерации обложки



