
Мат и убийства в фильмах Квентина Тарантино
Мат и убийства в фильмографии Квентина Тарантино
Квентин Тарантино является одним из моих любимых режиссеров. По этой причине я решила выбрать его основные кинематографические произведения основой для визуализации данных. Фильмы Тарантино славятся своей неприкрытой жестокостью, обилием кровопролитных сцен и яркими персонажами, которые становятся каноничными спустя некоторое время.
Исходя из этих факторов, с помощью визуализации данных мне было интересно ответить на 3 вопроса:
В каких фильмах Тарантино персонажи больше всего матерятся? В каких фильмах режиссера больше всего убийств? Есть ли взаимосвязь между этими аспектами?
Для визуализации я выбрала 4 вида диаграмм:
1. Линейная 2. Столбчатая 3. Круговая 4. Точечная
Этапы работы:

Основной цвет диаграмм — красный, он является одним из самых знаковых цветов в творчестве Квентина Тарантино, что я отразила в визуализации. Текст диаграмм — Helvetica, так как он ассоциируется с напечатанными сценариями фильмов.
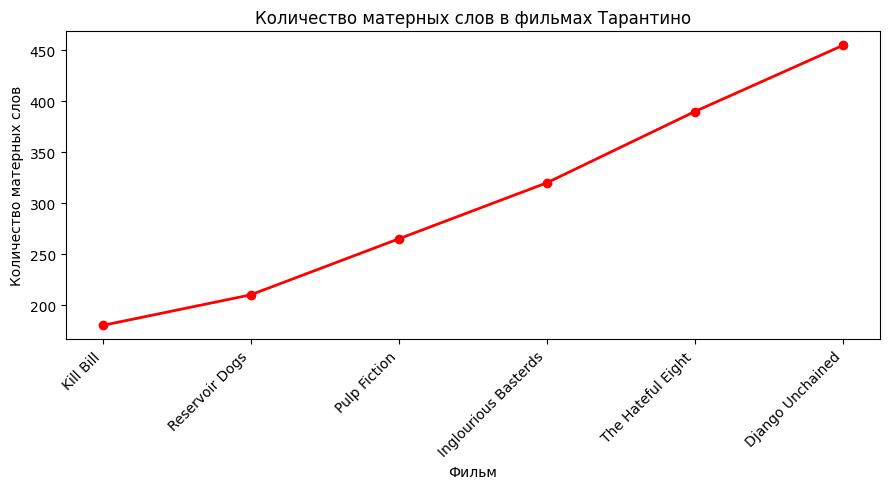
1. Количество матерных слов в фильмах Квентина Тарантино
import pandas as pd import matplotlib.pyplot as plt from matplotlib import rcParams
rcParams['font.family'] = 'Helvetica' rcParams['font.weight'] = 'light'
data = { «movie»: [ «Pulp Fiction», «Reservoir Dogs», «Kill Bill», «Inglourious Basterds», «Django Unchained», «The Hateful Eight» ], «Количество»: [ 265, 210, 180, 320, 455, 390 ] }
df_movies_word = pd.DataFrame (data).sort_values («Количество», ascending=True)
plt.figure (figsize=(9,5)) plt.plot ( df_movies_word[«movie»], df_movies_word[«Количество»], marker='o', color='red', linewidth=2 )
plt.title («Количество матерных слов в фильмах Тарантино») plt.xlabel («Фильм») plt.ylabel («Количество матерных слов») plt.xticks (rotation=45, ha="right»)
plt.tight_layout () plt.show ()
2. Самые частые матерные слова в фильме «Криминальное чтиво»
import pandas as pd import matplotlib.pyplot as plt from matplotlib import rcParams
rcParams['font.family'] = 'Helvetica' rcParams['font.weight'] = 'light'
data = { «movie»: [«Pulp Fiction»] * 30, «type»: [«word»] * 30, «word»: [ «fuck»,"shit»,"fuck»,"fuck»,"shit»,"damn»,"fuck»,"bitch»,"shit»,"fuck», «damn»,"fuck»,"shit»,"fuck»,"bitch»,"fuck»,"shit»,"fuck»,"damn»,"fuck», «fuck»,"shit»,"fuck»,"damn»,"fuck»,"shit»,"fuck»,"bitch»,"fuck»,"shit» ] }
df = pd.DataFrame (data)
df_movies_curses = ( df[(df[«type»] == «word») & (df[«movie»] == «Pulp Fiction»)] .value_counts («word») .reset_index (name="Частота») .sort_values («Частота», ascending=False) .head (10) )
plt.figure (figsize=(7,4)) plt.bar ( df_movies_curses[«word»], df_movies_curses[«Частота»], color="red», edgecolor="black» )
plt.title («Самые частые матерные слова в фильме „Криминальное чтиво“») plt.xlabel («Слово») plt.ylabel («Количество употреблений») plt.xticks (rotation=45, ha="right»)
plt.tight_layout () plt.show ()
3. Количество убийств в фильмах Тарантино
import pandas as pd import matplotlib.pyplot as plt from matplotlib import rcParams
rcParams['font.family'] = 'Helvetica' rcParams['font.weight'] = 'light'
data = { «movie»: [ «Pulp Fiction», «Reservoir Dogs», «Kill Bill», «Inglourious Basterds», «Django Unchained», «The Hateful Eight» ], «Количество_убийств»: [ 43, 52, 87, 120, 95, 110 ] }
df_kills = pd.DataFrame (data)
plt.figure (figsize=(6,6)) plt.pie ( df_kills[«Количество_убийств»], labels=df_kills[«movie»], autopct='%1.1f%%', startangle=140, colors=['
FFD700', '
FF6347', '8A2BE2', '
00CED1', 'FF4500', '
228B22'] )plt.title («Распределение убийств по фильмам Тарантино») plt.tight_layout () plt.show ()
4. Связь количества убийств и матерных слов в фильмах Тарантино
import pandas as pd import matplotlib.pyplot as plt from matplotlib import rcParams
rcParams['font.family'] = 'Helvetica' rcParams['font.weight'] = 'light'
data = { «movie»: [ «Pulp Fiction», «Reservoir Dogs», «Kill Bill», «Inglourious Basterds», «Django Unchained», «The Hateful Eight» ], «Количество_убийств»: [43, 52, 87, 120, 95, 110], «Количество_матов»: [265, 210, 180, 320, 455, 390] }
df = pd.DataFrame (data)
plt.figure (figsize=(8,5)) plt.scatter ( df[«Количество_убийств»], df[«Количество_матов»], s=100, color='red', edgecolor='black' )
for i, movie in enumerate (df[«movie»]): plt.text (df[«Количество_убийств»][i]+1, df[«Количество_матов»][i]+2, movie, fontsize=10)
plt.title («Связь количества убийств и матерных слов в фильмах Тарантино») plt.xlabel («Количество убийств») plt.ylabel («Количество матерных слов»)
plt.tight_layout () plt.show ()
Итог:
Сопоставив данные графиков, можно сделать вывод, что между количеством матерных слов в фильме и убийствами нет особой взаимосвязи.
Самый матершинный фильм: «Джанго Освобожденный» Самое большое количество убийств в фильме: «Бесславные ублюдки»
Блокнот с кодом:
Датасет (ссылки)



