Анализ предикторов сосудистых патологий
Концепция
Меня, как и многих, заинтересовала парадоксальность инсульта: как болезнь с мгновенным проявлением может быть результатом долгих процессов, которые часто остаются незамеченными. Я решила узнать, что на самом деле стоит за сухой медицинской статистикой и повседневными представлениями. Мне хотелось разобраться, какие факторы риска являются распространённым мифом, а какие — суровой, реальностью. Поэтому я погрузилась в анализ данных.
Для проекта я взяла датасет Healthcare Dataset Stroke Data (5110 записей). Это не просто таблица, а срез реальных медицинских карт, включающий как клинические показатели (уровень глюкозы, ИМТ), так и социальные факторы (статус брака, тип жилья, профессия).
Почему именно эти данные?
Инсульт часто воспринимается как внезапная катастрофа, но данные позволяют увидеть его как накопленный результат. Мне было важно проверить гипотезы: действительно ли «офисный планктон» рискует меньше, чем рабочие? И всегда ли лишний вес — это приговор? Этот проект — попытка уйти от поверхностных суждений к фактам, которые можно измерить и проверить.
Стилизация визуализаций
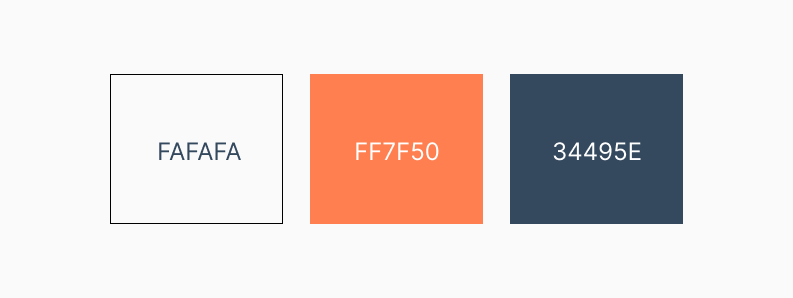
Так как стандартные графики Python выглядят слишком технично, я разработала стиль на основе скандинавского минимализма:
Для фона я выбрала: #FAFAFA. Это достаточно светлый оттенок, который создаёт ощущение «воздушности» и нейтральности.
Что касается основных цветов, я использовала:
Спокойный Индиго (#34495E) для обозначения нормы.
Мягкий Коралл (#FF7F50) для выделения зон риска.
Такая палитра позволяет избежать «визуального крика», характерного для чистого красного цвета, но при этом чётко акцентирует внимание на проблемных областях.
Визуальная стратегия
Для своего проекта я отказалась от примитивных пай-чартов. Для такой задачи нужны инструменты, показывающие плотность и распределение: KDE Plot (для возраста), Boxen Plot (для выбросов) и Heatmap (для корреляций).
Ход работы
Данные были «грязными»: 4% записей не имели индекса массы тела. Просто удалить их значило бы потерять часть картины, поэтому я использовала медианную импутацию (заполнение пропусков средним типичным значением). Для наглядности я написала код, который перевел все категориальные метки (Gender, Work Type) на русский язык.
Для выполнения проекта я загрузила и проанализировала структуру CSV-файла с данными.
После загрузки данных я определила основные этапы анализа:
1. Построила график распределения пациентов, чтобы оценить сбалансированность данных по целевой переменной.
2. Проанализировала распределение по возрастным группам.
3. Определила рейтинг профессий по уровню риска.
4. Выявила ключевые закономерности, влияющие на вероятность инсульта.
5. Исследовала влияние статуса курения на метаболические показатели.
6. На итоговом графике обобщила основные находки исследования.
Для каждого из этапов я визуализировала графики, на основе которых сделала выводы.
Результаты анализа
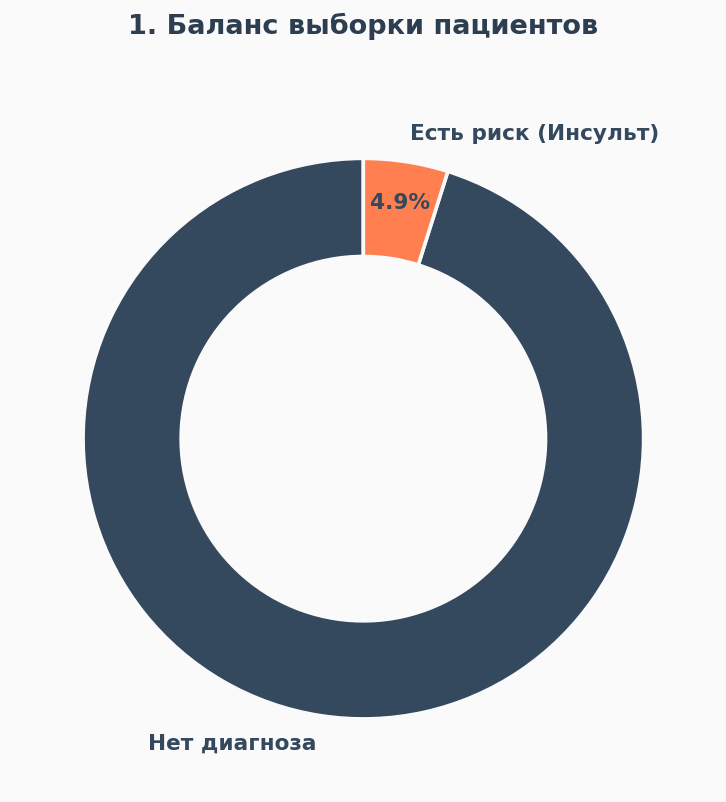
Первое, на что я обратила внимание — это дисбаланс данных. Круговая диаграмма показывает, что случаи инсульта составляют менее 5% от всей выборки.
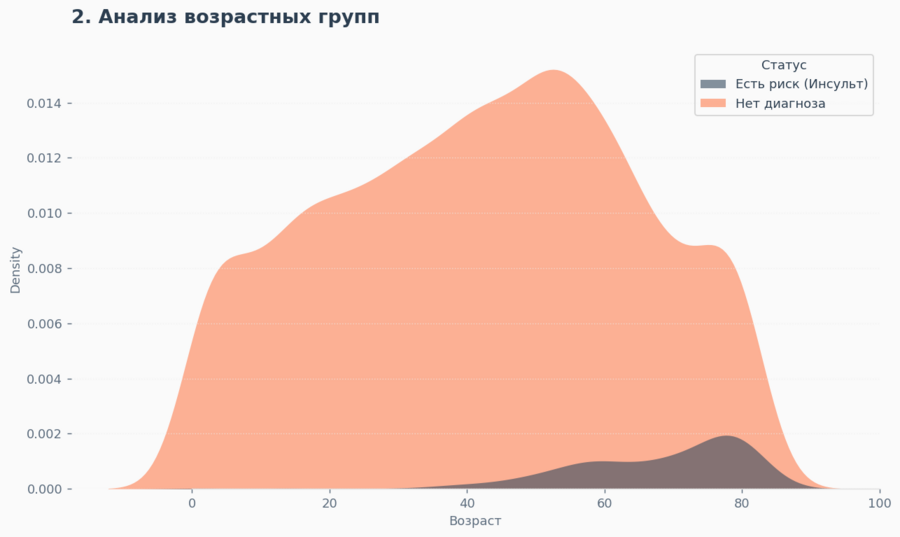
В свою очередь, график плотности показывает не только очевидный пик риска после 55 лет, но и тревожный «хвост» в зоне 40–45 лет. Это сигнал о том, что мониторинг нужно начинать раньше.
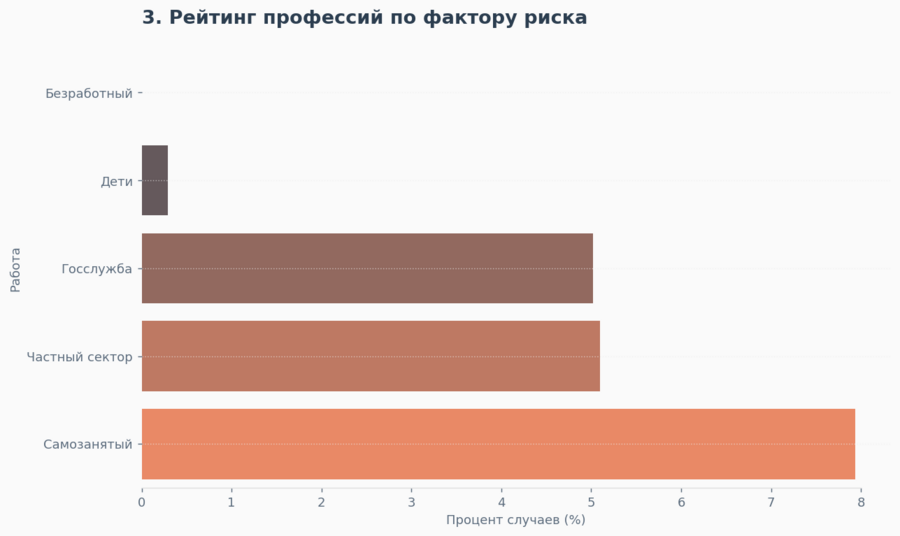
Затем я решила сделать анализ по профессиям, где выяснила, что фрилансеры и самозанятые (Self-employed) болеют чаще, чем сотрудники частных компаний. Вероятно, отсутствие нормированного графика и стресс — более сильные факторы риска, чем офисная гиподинамия.
Точечная диаграмма (Scatter Plot) разрушила стереотип. Мы видим множество пациентов с нормальным весом, но с инсультом. Общий знаменатель у них — уровень глюкозы выше 200. Это доказывает, что сахар в крови — куда более точный маркер опасности, чем цифра на весах.


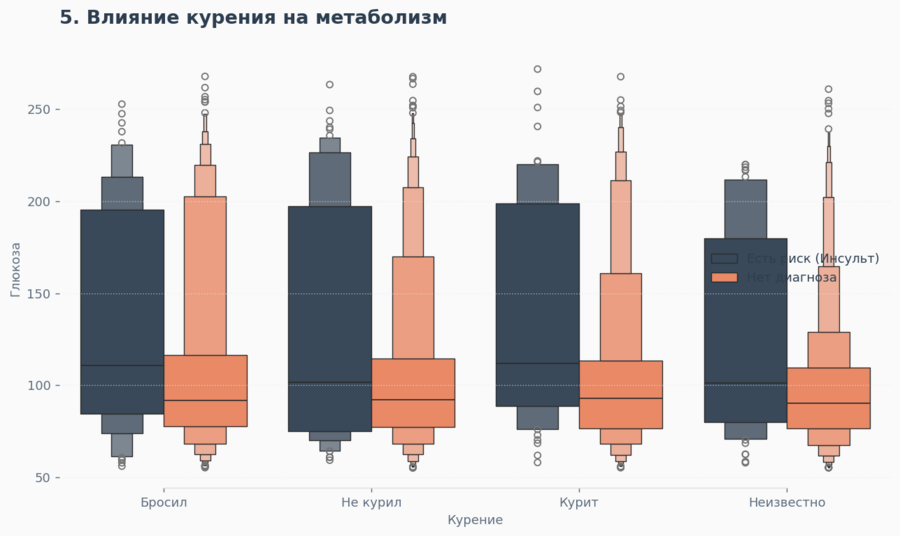
На этом графике я исследовала «хвосты» распределения. Интересно, что у группы риска (инсульт) медианный уровень глюкозы выше во всех категориях — и у курильщиков, и у тех, кто бросил. Это говорит о том, что высокий сахар — более универсальный маркер патологии, чем статус курения сам по себе.

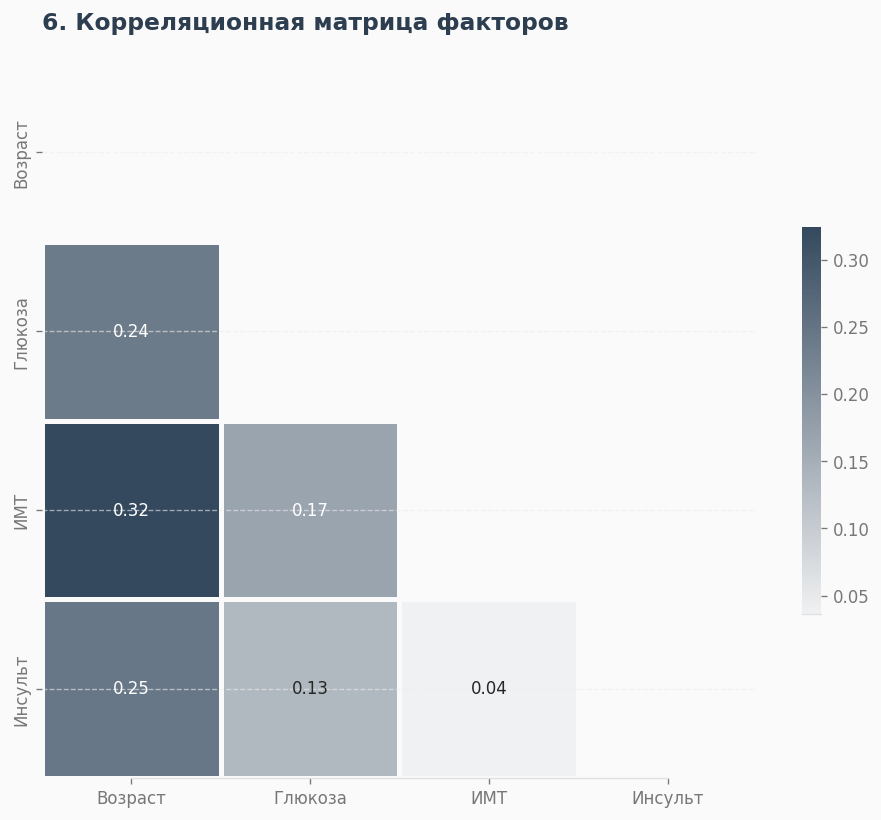
Тепловая карта подводит итог. Самая яркая связь (коэффициент 0.25) — между возрастом и инсультом. На втором месте — уровень глюкозы, а вот ИМТ (вес) имеет куда меньшую корреляцию. Цифры подтвердили гипотезу: возраст и сахар — два главных столпа диагностики.

Итог
Когда я начинала этот проект, я ожидала увидеть банальные истины: «старость и лишний вес — главные враги». Но данные рассказали другую историю — гораздо более сложную и неожиданную, и это заставило меня полностью пересмотреть свои взгляды.
Мы привыкли бояться в первую очередь цифры на весах, но анализ показал, что высокий уровень сахара в крови «работает» тише и зачастую вернее, поражая в том числе и тех, кто внешне выглядит совершенно стройным. Мы часто романтизируем фриланс как путь к свободе и здоровью, а статистика недвусмысленно говорит: самозанятые, особенно в условиях нестабильности, выгорают и сталкиваются с рисками чаще, чем защищённые трудовым договором офисные сотрудники.
Таким образом, данные развернули картину на 180 градусов — от очевидных, почти бытовых страхов к скрытым и системным рискам, о которых мы говорим гораздо реже.
Нейросети
В работе над проектом я использовала нейросеть DeepSeek-V3 (ссылка: chat.deepseek.com).
Честно говоря, работа с библиотекой matplotlib иногда превращается в мучение: нужно помнить десятки параметров, чтобы просто убрать рамку или перекрасить сетку. Я решила делегировать эту техническую рутину ИИ.
Как именно я её использовала:
Я не хотела тратить часы на подбор hex-кодов. Я написала промпт: «Напиши функцию на Python для seaborn, которая применит стиль 'Nordic Clean': убери лишние рамки (spines), сделай фон светло-серым (#FAFAFA), а шрифт темно-серым. Основные цвета должны быть индиго и коралловый». Нейросеть выдала готовый блок кода с настройками plt.rcParams и функцию style_chart (). Я просто скопировала это в свой проект, и все графики сразу стали выглядеть профессионально и в едином стиле. Это сэкономило мне минимум 2 часа верстки.



