
Анализ SSENSE Fashion Dataset
Описание
Для анализа я выбрала датасет SSENSE Fashion Dataset, найденный на платформе Kaggle. Мне было интересно работать именно с этими данными, так как я являюсь студенткой факультета «Дизайн одежды» (направление «Мода»), а датасет отражает реальный ассортимент, бренды и ценовую политику современной fashion-индустрии. Данные являются содержательными и аналитически интересными: они включают 19 919 строк и 4 столбца, информацию о 631 бренде, что позволяет выявлять тренды, сравнивать бренды и анализировать структуру рынка.
Используемые виды визуализаций: 1. Облако слов (для анализа частоты брендов) 2. Диаграмма «Ящик с усами» (для изучения распределения цен и выбросов) 3. Круговая диаграмма (для изучения распределения товаров по типу одежды) 4. Гистограмма для 90% обычных товаров (для анализа типичного ценового диапазона) 5. Гистограмма для 10% самых дорогих товаров (для анализа люксового сегмента)
Стилизация
Я выбрала чёрный и белый как базовые универсальные цвета, а также графитовый серый (2E2E2E), холодный серо-голубой (AAB3B8) и приглушённый оливковый (7A8570), потому что они образуют минималистичную, сдержанную и гармоничную палитру. Эти цвета выглядят стильно и современно, не перегружают визуал.
Используемый шрифт — Montserrat-Bold

Nano Banana: просила надеть элемент одежды на модель из прикреплённого фото
Открытие CSV-данных, импорт библиотек, настройка палитры и шрифта
Изучающий анализ данный

Посмотрим сколько товаров у каждого бренда и их процент
В выборке больше всего товаров у бренда Gucci, далее идут Nike, Bottega Veneta, Rick Owens и Marni. Остальные бренды представлены заметно меньшим количеством товаров, многие из них всего одной позицией. Это говорит о том, что ассортимент сосредоточен вокруг нескольких популярных брендов, при большом количестве малопредставленных марок.
Дальше я решила визуализировать это с помощью облака слов, где размер слова показывает его частоту.
ChatGPT 5.2: просила написать Python-код для облака слов по брендам
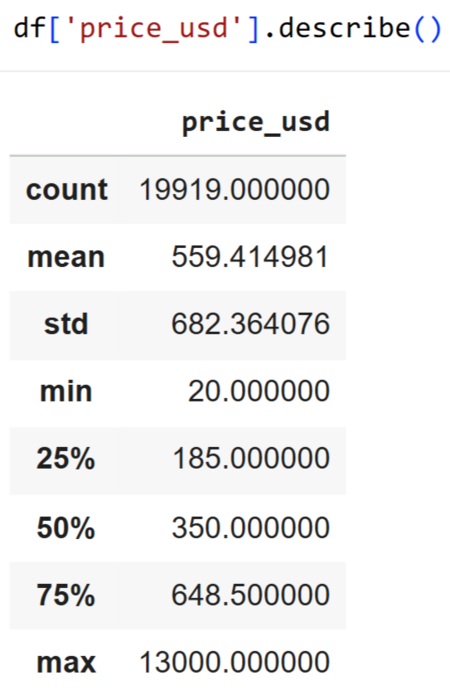
Рассмотрим распределение цены на товары
Средняя цена выше медианы, это значит есть очень дорогие товары, которые тянут среднее значение вверх, например Bottega Veneta Tan Croc-Embossed Leather Coat за 13 000 usd (максимальная цена в данном датасете).
Здесь я визуализировала распределение цен с помощью диаграммы «Ящик с усами», которая показывает медиану, разброс значений и наличие выбросов.
ChatGPT 5.2: попросила написать Python-код для boxplot распределения цен
Изучим распределение товаров по типу одежды.
Ассортимент разделён на мужскую и женскую категории. На удивление, мужских товаров в датасете оказалось больше, чем женских.
ChatGPT 5.2: попросила написать Python-код для pie chart распределения товаров по типу одежды
Объясняющий анализ данных
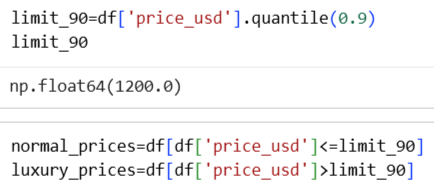
Выбросы в данном датасете являются нормальной ситуацией, так как рынок одежды включает товары разных ценовых категорий: от более доступных до люксовых. Чтобы наглядно объяснить это, далее я отдельно рассмотрю распределение цен для 90% обычных товаров и для 10% самых дорогих позиций, которые формируют выбросы.
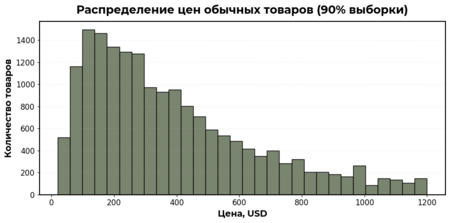
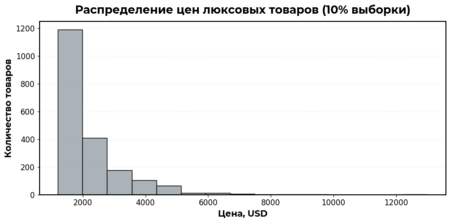
ChatGPT 5.2: попросила написать Python-код для гистограмм цен 90% обычных и 10% самых дорогих товаров
По графикам видно, что большая часть товаров относится к обычному ценовому сегменту. При этом почти 1200 товаров находятся в диапазоне от 1200 до 2000 долларов, более 600 товаров от 2000 до 4000 долларов, и даже выше 4000 долларов остаётся заметное количество позиций.
Это показывает, что выбросы в данных связаны с реальными люксовыми товарами, которые, как и в жизни, сильно отличаются по цене и поэтому требуют отдельного рассмотрения.
Вывод
В данной работе я проанализировала датасет с товарами интернет-магазина SSENSE, который содержит информацию о брендах, типах одежды и ценах. Эти данные показались мне интересными, так как они отражают реальный fashion-рынок с разными ценовыми сегментами: от более доступных до люксовых.
В ходе анализа я использовала разные виды визуализаций: облако слов для брендов, диаграмму «ящик с усами» и гистограммы для анализа распределения цен и выбросов, а также круговую диаграмму для изучения типов одежды. Для обработки данных применялись методы описательной статистики, подсчёта частот и долей, а также разделение товаров на обычные и люксовые.
Все графики были оформлены в едином стиле с ограниченной цветовой палитрой и шрифтом Montserrat Bold. В результате удалось показать как изучающий, так и объясняющий анализ данных и сделать вывод, что выбросы в датасете связаны с реальным присутствием люксовых товаров.
Описание применения генеративной модели
В работе я использовала генеративные модели для оформления проекта. Модель Nano Banana помогла объединить подобранные мной предметы одежды в один образ на манекене, чтобы наглядно показать цветовую палитру и стиль презентации. ChatGPT 5.2 я использовала для написания кода и создания графиков в едином стиле со шрифтом и цветами, выбранными для проекта.
Промпты:
1. Nano Banana: Изучи прикреплённую фотографию модели, запомни её внешность, позу и пропорции тела. После этого надень на эту же модель элемент одежды с прикреплённого изображения (штаны/пиджак/туфли), сохрани реалистичную посадку, пропорции фигуры и естественный вид
2. ChatGPT 5.2: У меня есть датафрейм с колонкой brand. Я хочу на основе этой колонки сделать визуализацию в виде облака слов. Напиши код на Python, чтобы размер слов зависел от частоты брендов. Цвета облака должны быть в ограниченной палитре: чёрный (000000), белый (FFFFFF), графитовый (2E2E2E), серо-голубой (AAB3B8) и оливковый (7A8570), а шрифт «Моnstserrat-Bold». Визуализация должна быть простой и аккуратной
3. ChatGPT 5.2: Теперь давай построим boxplot, ящик с усами по переменной «price_usd», цвета графика должны быть также в ограниченной палитре: чёрный (000000), белый (FFFFFF), графитовый (2E2E2E), серо-голубой (AAB3B8) и оливковый (7A8570), а шрифт «Моnstserrat-Bold»
4. ChatGPT 5.2: Теперь давай построим pie chart по переменной «type», цвета графика должны быть также в ограниченной палитре: чёрный (000000), белый (FFFFFF), графитовый (2E2E2E), серо-голубой (AAB3B8) и оливковый (7A8570), а шрифт «Моnstserrat-Bold»
5. ChatGPT 5.2: Для переменной «normal_prices» построй гистограмму, цвета графика должны быть также в ограниченной палитре: чёрный (000000), белый (FFFFFF), графитовый (2E2E2E), серо-голубой (AAB3B8) и оливковый (7A8570), а шрифт «Моnstserrat-Bold»
6. ChatGPT 5.2: Для переменной «luxury_prices» также построй гистограмму. Теперь основной цвет сделай голубой, но цвета графика все равно должны быть также в ограниченной палитре: чёрный (000000), белый (FFFFFF), графитовый (2E2E2E), серо-голубой (AAB3B8) и оливковый (7A8570), а шрифт «Моnstserrat-Bold»
Датасет и блокнот



