Проект по анализу данных и визуализации
какие данные выбрали и где вы их нашли
Я выбрала массив данных с предложенного сайта https://yandex.ru/project/oda/useful. Внима-ние привлек портал открытых данных Правительства Москвы, из которого я взяла для исследо-вания Ботанической коллекции парка «Зарядье», потому что меня всегда привлекала ботаника, а еще потому что у этого массива данных в отличие от остальных стояли пять звезд на сайте.
портал открытых данных, 5 звезд на ботанической коллекции
графики
вертикальная столбчатая диаграмма (показывает, как растения распределены по различным ландшафтным зонам парка)
тепловая карта корреляций (показывает взаимосвязь между числовыми показателями коллекции)
круговая диаграмма формы осмотра (демонстрирует распределение растений по способам осмотра территории)
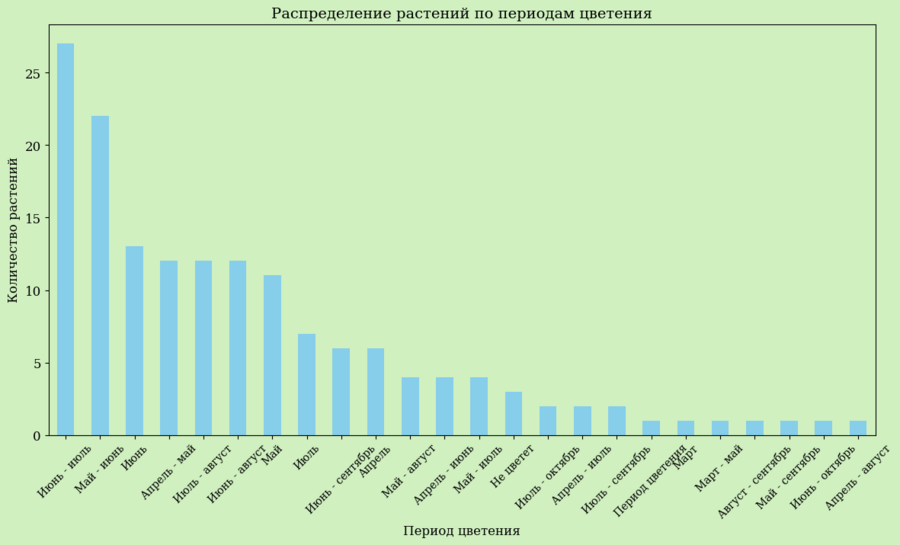
столбчатая диаграмма периодов цветения (демонстрирует распределение растений по временным периодам цветения)
Все диаграммы стилизованы с цветовым оформлением фона (#d0f0c0), который я выбрала потому что зеленый подходит под тему растений и шрифтом DejaVu Serif, тк Comic Sans MS, который я предполагала использовать изначально, в гугл коллаб изначально не было, а времени осталось очень мало.
как я обрабатывала данные
В чат яндекс AI я прикрепила нужный файл и написала задачу «напиши код который мог бы с по-мощью Pandas провести анализ данных и визуализацию в питоне»
изначальный код
Изначальный код:
Импортируем необходимые библиотеки
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np
Загружаем данные
df = pd.read_csv ('data-60861-05.09.2025.csv', sep='; ', encoding='utf-8')
Преобразуем типы данных
df['ID'] = df['ID'].astype (int)
Базовые характеристики датасета
print («Общая информация о датасете:») print (df.info ()) print («\nПервые 5 строк:») print (df.head ())
Анализ пропущенных значений
print («\nПропущенные значения:») print (df.isnull ().sum ())
Статистический анализ
print («\nСтатистические характеристики:») print (df.describe ())
Анализ ландшафтных зон
zone_counts = df['LandscapingZone'].value_counts () print («\nРаспределение по ландшафтным зонам:») print (zone_counts)
Визуализация распределения растений по зонам
plt.figure (figsize=(12, 6)) sns.countplot (y=df['LandscapingZone'], order=zone_counts.index, palette='viridis') plt.title ('Распределение растений по ландшафтным зонам') plt.xlabel ('Количество растений') plt.ylabel ('Ландшафтная зона') plt.show ()
Анализ периодов цветения
df['ProsperityPeriod'] = df['ProsperityPeriod'].str.strip ()
Группировка по периодам цветения
bloom_periods = df['ProsperityPeriod'].value_counts () print («\nРаспределение по периодам цветения:») print (bloom_periods)
Визуализация периодов цветения
plt.figure (figsize=(14, 7)) bloom_periods.plot (kind='bar', color='skyblue') plt.title ('Распределение растений по периодам цветения') plt.xlabel ('Период цветения') plt.ylabel ('Количество растений') plt.xticks (rotation=45) plt.show ()
Корреляционный анализ (для числовых данных)
corr_matrix = df.corr () print («\nКорреляционная матрица:») print (corr_matrix)
Тепловая карта корреляций
plt.figure (figsize=(10, 8)) sns.heatmap (corr_matrix, annot=True, cmap='coolwarm', fmt=».2f») plt.title ('Корреляция между числовыми признаками') plt.show ()
Анализ формы осмотра
view_form = df['ViewForm'].value_counts () print («\nРаспределение по форме осмотра:») print (view_form)
Круговая диаграмма формы осмотра
plt.figure (figsize=(8, 8)) plt.pie (view_form, labels=view_form.index, autopct='%1.1f%%', startangle=140, col-ors=plt.cm.Pastel1.colors) plt.title ('Распределение по форме осмотра') plt.show ()
Возникла ошибка, скриншот которой я прикрепила к заданию, также добавила ошибочный код полностью и написала чату гпт: «Исправь код учитывая ошибку и напиши его заново без ошибок». Таким образом код был переработан и отображал нужные мне графики. Они не были стилизованы, мне нужно было убедиться, что все работает-ка надо. Посреди графиков все еще всплывала ошибка, но я решила разобраться с ней позже.
скриншот первой ошибки
Далее я определилась с цветом и шрифтом и написала в чате задачу, прикрепив к ней переработанный код: «измени данный код таким образом, чтобы визуализация данных была стилизована. Фон должен быть цвета вот с этим кодом: #d0f0c0, а шрифт должен быть Comic Sans MS.» В коде снова возникла ошибка (графики не отображались) и я снова переработала его уже знакомым мне методом.
вторая ошибка
промежуточный код
Промежуточный код (часть1) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np
Убираем plt.style.use ('seaborn-whitegrid') — это вызывает ошибку
Вместо этого настраиваем параметры визуализации вручную
plt.rcParams['figure.facecolor'] = '
d0f0c0'
Цвет фона графиков plt.rcParams['font.family'] = 'Comic Sans MS' # Шрифт plt.rcParams['font.size'] = 12 # Размер шрифта plt.rcParams['axes.facecolor'] = 'd0f0c0'
Цвет фона осей plt.rcParams['axes.edgecolor'] = 'black' # Цвет границ осей plt.rcParams['xtick.color'] = 'black' # Цвет меток по X plt.rcParams['ytick.color'] = 'black' # Цвет меток по YЗагружаем данные
df = pd.read_csv ('data-60861-05.09.2025.csv', sep='; ', encoding='utf-8')
Преобразуем типы данных с обработкой нечисловых значений
df['ID'] = pd.to_numeric (df['ID'], errors='coerce').astype ('Int64')
Базовые характеристики датасета
print («Общая информация о датасете:») print (df.info ()) print («\nПервые 5 строк:») print (df.head ())
Анализ пропущенных значений
print («\nПропущенные значения:») print (df.isnull ().sum ())
Статистический анализ
print («\nСтатистические характеристики:») print (df.select_dtypes (include=[np.number]).describe ())
Анализ ландшафтных зон
zone_counts = df['LandscapingZone'].value_counts () print («\nРаспределение по ландшафтным зонам:») print (zone_counts)
Визуализация распределения растений по зонам
plt.figure (figsize=(12, 6)) sns.countplot (y=df['LandscapingZone'], order=zone_counts.index, palette='viridis') plt.title ('Распределение растений по ландшафтным зонам', fontsize=14, fontname='Comic Sans MS') plt.xlabel ('Количество растений', fontsize=12, fontname='Comic Sans MS') plt.ylabel ('Ландшафтная зона', fontsize=12, fontname='Comic Sans MS') plt.gca ().set_facecolor ('
d0f0c0')
Цвет фона для графика plt.show ()Анализ периодов цветения
df['ProsperityPeriod'] = df['ProsperityPeriod'].str.strip ()
Группировка по периодам цветения
bloom_periods = df['ProsperityPeriod'].value_counts () print («\nРаспределение по периодам цветения:») print (bloom_periods)
Промежуточный код (часть2)
Визуализация периодов цветения
plt.figure (figsize=(14, 7)) bloom_periods.plot (kind='bar', color='skyblue') plt.title ('Распределение растений по периодам цветения', fontsize=14, fontname='Comic Sans MS') plt.xlabel ('Период цветения', fontsize=12, fontname='Comic Sans MS') plt.ylabel ('Количество растений', fontsize=12, fontname='Comic Sans MS') plt.xticks (rotation=45, fontsize=10, fontname='Comic Sans MS') plt.gca ().set_facecolor ('#d0f0c0') plt.show ()
Корреляционный анализ
numeric_df = df.select_dtypes (include=[np.number]) if len (numeric_df.columns) > 1: corr_matrix = numeric_df.corr () print («\nКорреляционная матрица:») print (corr_matrix)
# Тепловая карта корреляций
plt.figure (figsize=(10, 8))
sns.heatmap (corr_matrix, annot=True, cmap='coolwarm', fmt=».2f»,
annot_kws={"size»: 10, «fontname»: «Comic Sans MS"})
plt.title ('Корреляция между числовыми признаками', fontsize=14, fontname='Comic Sans MS')
plt.gca ().set_facecolor ('#d0f0c0')
plt.show ()
else: print («Нет числовых данных для корреляционного анализа.»)
Анализ формы осмотра
view_form = df['ViewForm'].value_counts () print («\nРаспределение по форме осмотра:») print (view_form)
Круговая диаграмма формы осмотра
plt.figure (figsize=(8, 8)) plt.pie (view_form, labels=view_form.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Pastel1.colors, textprops={'fontsize': 10, 'fontname': 'Comic Sans MS'}) plt.title ('Распределение по форме осмотра', fontsize=14, fontname='Comic Sans MS') plt.gca ().set_facecolor ('#d0f0c0') plt.show ()
Наконец я добралась до той незначительной ошибки посередине и снова переработала код, используя привычный метод.
ошибка в графиках
Затем, увидев что между зелеными блоками некрасиво чередуются числовые данные, я вручную поменяла части кода местами так, чтобы выглядело визуально привлекательнее.
В гугл коллабе не оказалось нужного шрифта и я выбрала первый поправшийся из имеющихся, это был DejaVu Serif. Заменила весь комик санс на новый шрифт в чате гпт с помощью команды «Замени везде в коде шрифт Comic Sans MS на шрифт DejaVu Serif и полностью перепиши код, не трогая все остальное.»
итоговый код
Итоговый код (часть1) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import numpy as np
Настройка параметров визуализации
plt.rcParams['figure.facecolor'] = '
d0f0c0'
Цвет фона графиков plt.rcParams['font.family'] = 'DejaVu Serif' # Изменённый шрифт plt.rcParams['font.size'] = 12 # Размер шрифта plt.rcParams['axes.facecolor'] = 'd0f0c0'
Цвет фона осей plt.rcParams['axes.edgecolor'] = 'black' # Цвет границ осей plt.rcParams['xtick.color'] = 'black' # Цвет меток по X plt.rcParams['ytick.color'] = 'black' # Цвет меток по YЗагрузка данных
df = pd.read_csv ('data-60861-05.09.2025.csv', sep='; ', encoding='utf-8')
Обработка данных
df['ID'] = pd.to_numeric (df['ID'], errors='coerce').astype ('Int64')
Базовые характеристики
print («Общая информация о датасете:») print (df.info ()) print («\nПервые 5 строк:») print (df.head ())
Анализ пропусков
print («\nПропущенные значения:») print (df.isnull ().sum ())
Статистический анализ
print («\nСтатистические характеристики:») print (df.select_dtypes (include=[np.number]).describe ())
Анализ ландшафтных зон
zone_counts = df['LandscapingZone'].value_counts () print («\nРаспределение по ландшафтным зонам:») print (zone_counts)
Анализ периодов цветения
df['ProsperityPeriod'] = df['ProsperityPeriod'].str.strip () bloom_periods = df['ProsperityPeriod'].value_counts () print («\nРаспределение по периодам цветения:») print (bloom_periods)
Визуализация распределения по зонам
plt.figure (figsize=(12, 6)) sns.histplot (data=df, y='LandscapingZone', hue='LandscapingZone', multiple='stack', shrink=0.8, palette='viridis', legend=False) plt.title ('Распределение растений по ландшафтным зонам', fontsize=14, fontname='DejaVu Serif') plt.xlabel ('Количество растений', fontsize=12, fontname='DejaVu Serif') plt.ylabel ('Ландшафтная зона', fontsize=12, fontname='DejaVu Serif') plt.gca ().set_facecolor ('#d0f0c0') plt.show ()
итоговый код (часть2)
Визуализация периодов цветения
plt.figure (figsize=(14, 7)) bloom_periods.plot (kind='bar', color='skyblue') plt.title ('Распределение растений по периодам цветения', fontsize=14, fontname='DejaVu Serif') plt.xlabel ('Период цветения', fontsize=12, fontname='DejaVu Serif') plt.ylabel ('Количество растений', fontsize=12, fontname='DejaVu Serif') plt.xticks (rotation=45, fontsize=10, fontname='DejaVu Serif') plt.gca ().set_facecolor ('#d0f0c0') plt.show ()
Корреляционный анализ
numeric_df = df.select_dtypes (include=[np.number]) if len (numeric_df.columns) > 1: corr_matrix = numeric_df.corr () print («\nКорреляционная матрица:») print (corr_matrix)
plt.figure (figsize=(10, 8))
sns.heatmap (corr_matrix, annot=True, cmap='coolwarm', fmt=».2f»,
annot_kws={"size»: 10, «fontname»: «DejaVu Serif"})
plt.title ('Корреляция между числовыми признаками', fontsize=14, fontname='DejaVu Serif')
plt.gca ().set_facecolor ('#d0f0c0')
plt.show ()
else: print («Нет числовых данных для корреляционного анализа.»)
Анализ формы осмотра
view_form = df['ViewForm'].value_counts () print («\nРаспределение по форме осмотра:») print (view_form)
Круговая диаграмма формы осмотра
plt.figure (figsize=(8, 8)) plt.pie (view_form, labels=view_form.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Pastel1.colors) plt.title ('Распределение по форме осмотра') plt.show ()
для обложки я обработала в прокрейте (программа фоторедактор) одну из получившихся диаграмм



